请注意,本文编写于 417 天前,最后修改于 417 天前,其中某些信息可能已经过时。
目录
Resource Info Paper https://arxiv.org/abs/2305.04764 Code & Data https://github.com/ZJU-ACES-ISE/ChatUniTest Public FSE Date 2024.12.14
Summary Overview
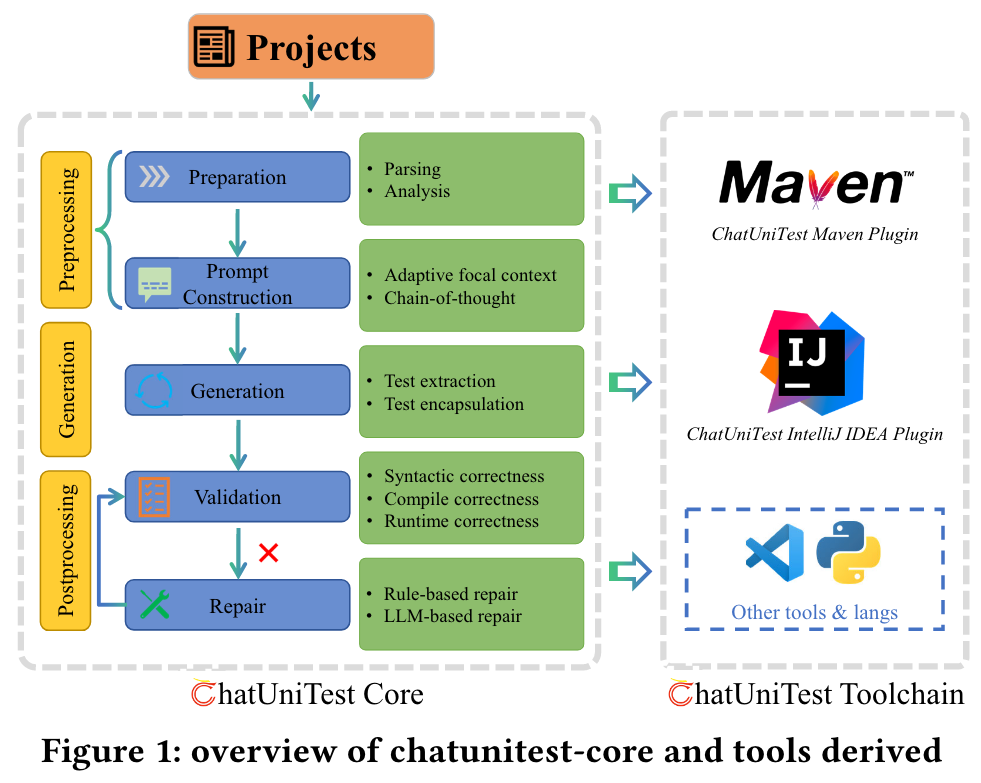
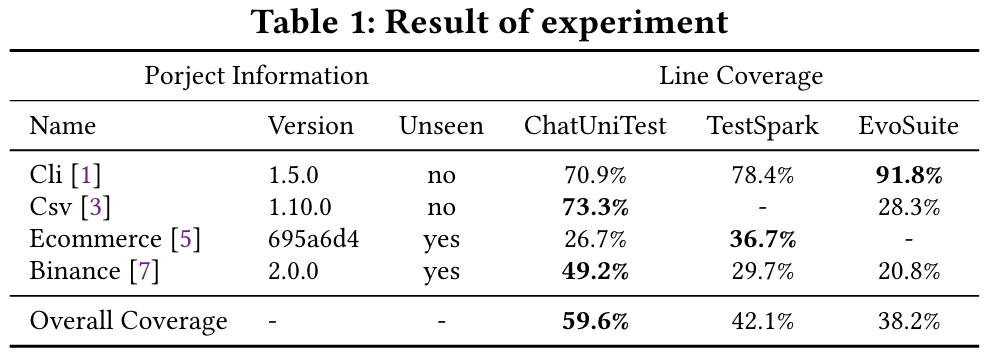
本文介绍了基于LLM的自动化单元测试生成框架ChatUnitTest。ChatUniTest结合了一种自适应焦点上下文机制,以在提示中包含有价值的上下文,并遵守生成验证修复机制,以纠正生成的单元测试中的错误。随后,我们开发了ChatUniTest Core,这是一个实现核心工作流程的通用库,并由ChatUniTest工具链补充,这是一套无缝集成的工具,可增强ChatUniTest的功能。
Main Content
Two primary limitations:
- the constraint on context length imposes a limitation on the capacity of LLMs to process all relevant information and generate a comprehensive unit test.
- due to insufficient validation mechanisms, LLMs often produce incorrect tests with various errors, such as "cannot find symbol" during compilation and "AssertionFailedError" during runtime, which require considerable effort for manual repair.
Case Study


🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性:
- 首次系统性评估开源LLM在单元测试生成中的表现:论文是第一个全面研究开源大型语言模型(LLMs)在单元测试生成任务中的有效性,并与商业化闭源模型(如GPT-4)以及传统方法(如Evosuite)进行了对比。这为后续研究提供了一个重要的基准。
- 多维度分析LLM的单元测试生成能力:通过四个研究问题(如提示设计的影响、上下文学习方法的有效性等),论文从提示设计、上下文学习方法、模型规模与结构等多个维度分析了LLM在单元测试生成中的表现。
- 提出了针对提示设计和上下文学习的优化建议:论文揭示了提示内容和风格对生成结果的显著影响,并指出了不同模型在处理提示时的差异性。这些结论为未来优化LLM的提示设计提供了重要的指导。
- 深入分析了LLM生成单元测试的局限性:论文总结了LLM生成单元测试的主要问题,如代码幻觉(hallucination)导致的语法错误、低效的缺陷检测能力等,并提出了后处理和输入变异等改进方向。
-
论文中存在的问题及改进建议:
- 对提示设计的研究不够全面:论文仅采用了移除单个代码特征的消融实验来评估提示设计的影响,但未探索不同代码特征组合的可能性。改进建议是引入组合优化方法(如遗传算法)来探索最佳提示设计。
- 上下文学习方法的适配性不足:论文仅适配了CoT(Chain-of-Thought)和RAG(Retrieval Augmented Generation)两种方法,但未考虑其他可能更适合单元测试生成的上下文学习方法(如自修复、自一致性等)。建议扩展研究范围,探索更多上下文学习策略。
- 未充分解决LLM生成测试的有效性问题:尽管论文分析了代码幻觉导致的错误类型,但未提出具体的后处理方法来修复这些错误。建议设计基于静态分析与LLM自修复结合的后处理框架。
- 缺乏对实际工业场景的验证:论文主要基于Defects4J基准进行实验,虽然具有代表性,但其覆盖的项目规模和领域有限。建议在更大规模的工业代码库(如GitHub上的开源项目)中验证其结论。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 研究路径1:提示设计的自动优化
基于遗传算法或强化学习,探索不同代码特征组合和描述风格对LLM单元测试生成效果的影响,以自动化生成最优提示。 - 研究路径2:上下文学习方法的任务适配
针对单元测试生成任务,设计和评估新的上下文学习方法,如基于错误反馈的自修复机制或基于测试覆盖率的动态提示调整策略。 - 研究路径3:高效后处理框架的开发
开发一个结合静态代码分析和LLM自修复能力的后处理框架,用于修复LLM生成的无效单元测试,提高其语法有效性和测试覆盖率。
- 研究路径1:提示设计的自动优化
-
为新的研究路径制定的研究方案:
-
研究路径1:提示设计的自动优化
- 研究方法:
- 使用遗传算法或强化学习框架生成不同的提示设计组合。
- 在Defects4J和更大规模的代码基准上评估每种提示设计的生成效果。
- 分析提示长度、代码特征选择和描述风格对生成有效性和覆盖率的影响。
- 研究步骤:
- 定义提示设计的搜索空间(如代码特征组合、描述风格等)。
- 使用遗传算法进行迭代优化,通过覆盖率和缺陷检测能力作为适应度函数。
- 对比优化后的提示与论文中的手动设计提示。
- 期望成果:
- 生成一组针对不同LLM的最优提示设计。
- 提供提示设计的自动化工具,降低使用LLM生成单元测试的门槛。
- 研究方法:
-
研究路径2:上下文学习方法的任务适配
- 研究方法:
- 设计基于错误反馈的自修复机制,将编译错误信息反馈给LLM以生成修复后的测试。
- 开发基于覆盖率的动态提示调整策略,根据生成测试的覆盖率动态调整提示内容。
- 研究步骤:
- 实现一个编译错误捕获模块,提取生成测试中的错误类型。
- 设计动态提示调整算法,根据覆盖率和错误类型实时优化提示。
- 在Defects4J和工业项目中验证新方法的有效性。
- 期望成果:
- 提出适配单元测试生成任务的上下文学习新方法。
- 显著提升LLM生成测试的有效性和覆盖率。
- 研究方法:
-
研究路径3:高效后处理框架的开发
- 研究方法:
- 结合静态代码分析技术,检测和修复LLM生成测试中的常见错误(如未解析符号、参数不匹配等)。
- 利用LLM的自修复能力,根据错误类型生成修复后的测试。
- 研究步骤:
- 开发一个静态分析工具链,自动识别生成测试中的语法和语义错误。
- 设计后处理规则,将错误反馈给LLM并生成修复建议。
- 在多种LLM和数据集上测试后处理框架的有效性。
- 期望成果:
- 提供一个通用的后处理框架,适配不同LLM和代码基准。
- 显著提高LLM生成测试的语法有效性和缺陷检测能力。
- 研究方法:
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录