目录
Resource Info Paper http://arxiv.org/abs/2502.17419 Code & Data https://github.com/zzli2022/Awesome-System2-Reasoning-LLM Public arXiv Date 2025.03.01
Main Content
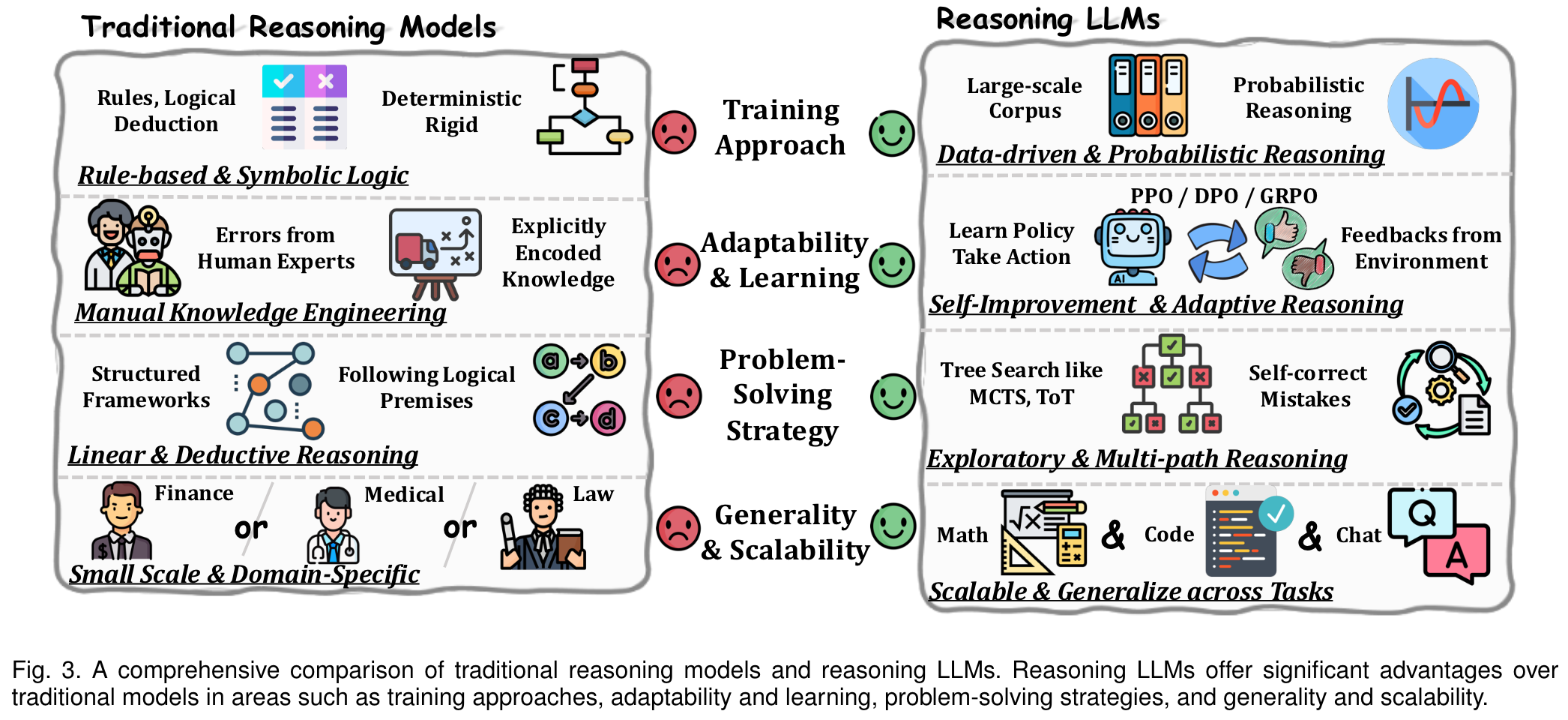
实现人类水平的智能需要完善从快速,直观 System1 到较慢,更故意的 System2 推理的过渡。虽然 System1 在迅速的启发式决策中表现出色,但System2 依赖于逻辑推理来进行更准确的判断和减少偏见。
推理LLM具有逐步处理信息的机制,使他们能够做出更准确,更合理的决策。
Monte Carlo Search
Four steps:
- Selection, which chooses the child node with the highest priority using the UCB1 formula:
where is the total reward of node , is its visit count, is the parent node's visit count, and balances exploration and exploitation.
- Expansion adds new nodes
- Simulation performs random rollouts to evaluate them
- Backpropagation updates node statistics.
MCTS has been widely used in tasks such as optimizing strategies in board games like GO and in robotic path planning, where it helps robots navigate dynamic enviornments effectively.
Analysis of the Features of Reasoning LLMs
Ouput Behaviour Perspective
Slow-thinking models engage in a latent generative process, particularly noticeable during the prediction of subsequent tokens.
Verification and Check Structure:
Analysis of OpenAI's o1 and o3 models indicates that their reasoning frameworks incorporate both macro-level actions for long-term strategic planning and micro-level actions, including "Wait", "Hold on", "Alternatively", and "Let's pause". These micro actions facilitate meticulous verification and iterative checking processes, ensuring precision in task execution.
Longer Inference Length & Time:
最近的研究表明,推理LLM通常会产生超过2000个令牌的产出,以解决编码和数学中的复杂问题。但是,这种扩展的输出长度有时会导致过度思考,在这种情况下,该模型在问题上花费了过多的时间,而无需改善解决方案。
Overly Cautious & Simple Problem Trap:
当前,推理LLM在竞争级数学,复杂编码,医学问题回答和多种方面的翻译等领域中表现出了强劲的性能。这些方案要求模型对问题进行细粒度分析,并根据给定条件执行仔细的逻辑推理。有趣的是,即使对于“ 2+3 =?”之类的直接问题,推理LLM也会表现出过度自信或不确定性。最近的研究指出,类似 o1 的模型倾向于生成多个解决方案回合,以方便数学问题,通常会探索不必要的路径。这种行为与缺乏更简单的问题的不同探索性动作形成鲜明对比,这表明该模型推理过程的效率低下。
Training Dynamic Perspective
Studies suggest that constructing Slow-thinking CoT datasets with a focus on hard samples leads to better generalization in fields like medicine and mathematics.
In comparison to simple CoT, Slow-thinking Supervised Fine-Tuning (SFT) data exhibits remarkable sample efficiency, often delivering comparable results with just 1/100th of the sample size.
Training LLMs for slow-thinking, as characterized by the LongCoT approach, results in relatively uniform gradient norms across different layeers. In contrast, fast-thinking, exemplified by the simplified CoT method, generates larger gradient magnitudes in the earlier layers, along with significant variability in gradient norms across layers.
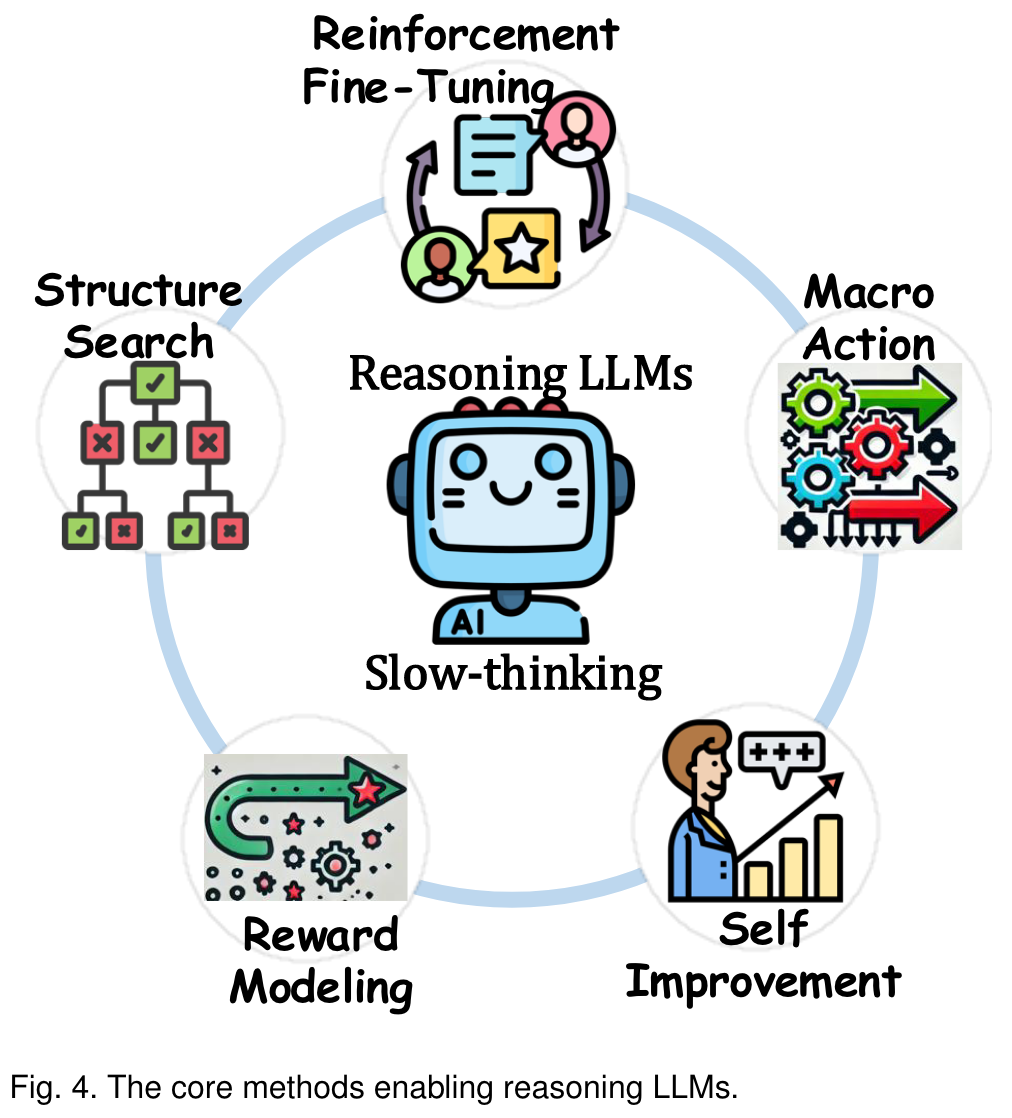
Core Method
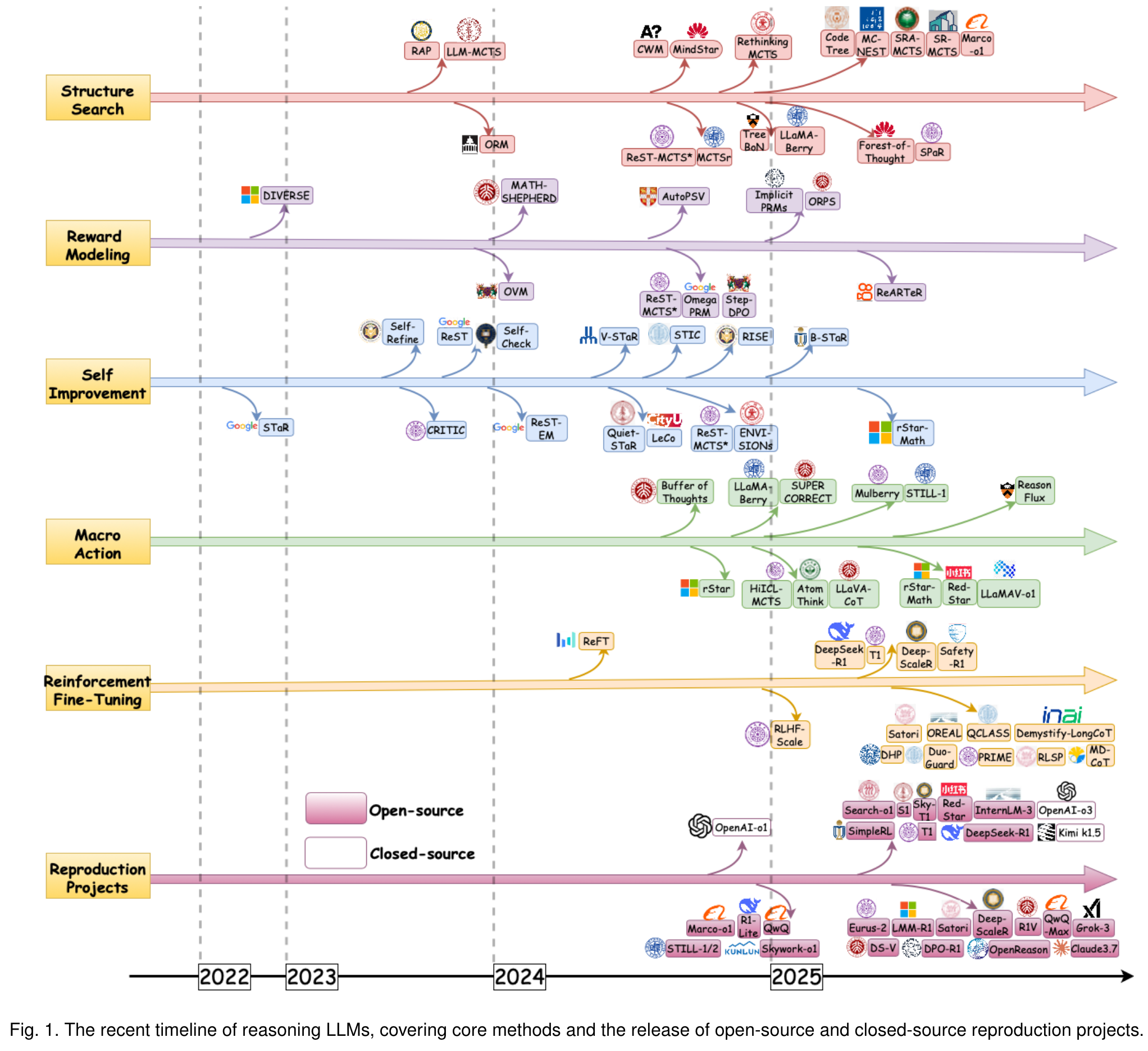
Structure Search
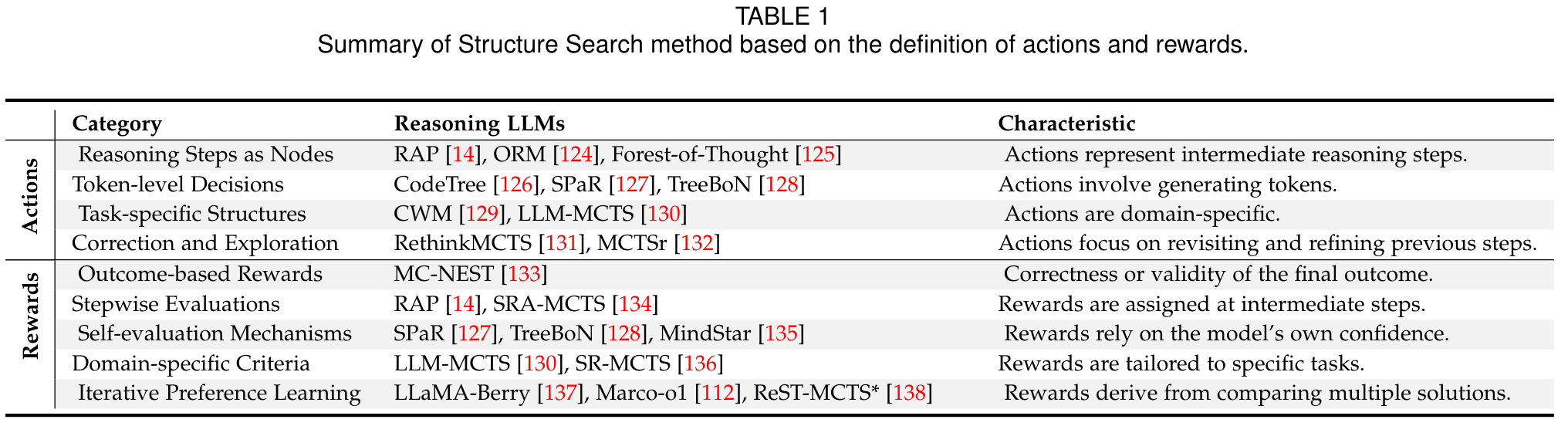
As shown in Table 1, we classify the actions in prior work into four categories:
- Reasoning Steps as Nodes: Actions represent intermediate reasoning steps or decisions, such as selecting rules, applying transformations, or generating subquestions.
- Token-level Decisions: Actions involve generating tokens or sequences (e.g., the next word, phrase, or code snippet).
- Task-specific Structures: Actions are domain-specific, such as moving blocks in blocksworld, constructing geometry in geometry problem-solving, or modifying workflows in task planning.
- Self-correction and Exploration: Actions forcus on revisiting, refining, or backtracking to improve previous reasoning steps.
Additionallye, as illustrated in Table 1, we classify the reward design into five categories:
- Outcome-based Rewards: Rewards focus on the correctness or validity of the final outcome or solution, including the validation of reasoning paths or task success.
- Stepwise Evaluations: Rewards are assigned at intermediate steps based on the quality of each step or its contribution toward the final outcome.
- Self-evaluation Mechanisms: Rewards rely on the model’s own confidence or self-assessment (e.g., likelihood, next-word probability, or confidence scores).
- Domain-specific Criteria: Rewards are tailored to specific tasks, such as symmetry and complexity in geometry or alignment with human preferences in text generation.
- Iterative Preference Learning: Rewards are derived from comparing multiple solutions or reasoning paths, guiding learning dynamically.
Reward Modeling
- Outcome supervision emphasizes the correctness of the final answer at a higher level of granularity, and the resulting model is referred to as the Outcome Reward Model (ORM).
- Process supervision provides step-by-step labels for the solution trajectory, evaluating the quality of each reasoning step. The resulting model is known as the Process Reward Model (PRM).
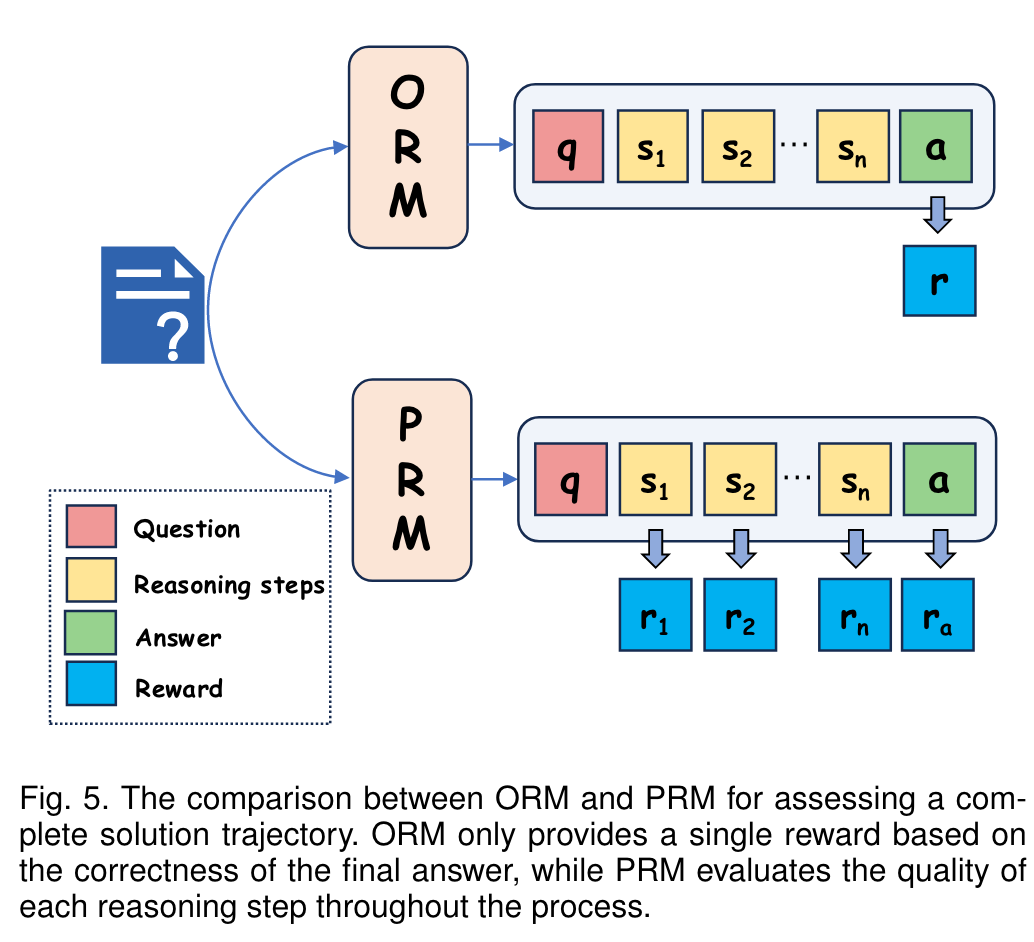
PRM offers significant advantages in complex reasoning tasks for several key reasons. First, it provides fine-grained, step-wise supervision, allowing for the identification of specific errors within a solution path. This feature is especially valuable for RL and automated error correction. Second, PRM closely mirrors human reasoning behavior, which relies on accurate intermediate steps to reach correct conclusions. Unlike ORM, PRM avoids situations where incorrect reasoning can still lead to a correct final answer, thus ensuring more robust and interpretable reasoning.
PRM face challenges:
- Lack of Explanations: Current PRMs often generate scores for reasoning steps without sufficient explanations, limiting interpretability and hindering their usefulness in refining reasoning during test-time.
- Bias in Training Data: Data collection methods, such as MCTS, tend to introduce distributional biases, assigning disproportionately higher scores to majority of questions. As a result, PRMs struggle to effectively identify erroneous reasoning steps.
- Early-Step Bias: PRMs show lower accuracy in predicting rewards for earlier reasoning steps compared to those closer to the final answer. This issue stems from the increased randomness and uncertainty associated with the initial steps in the reasoning process.
Self Improvement

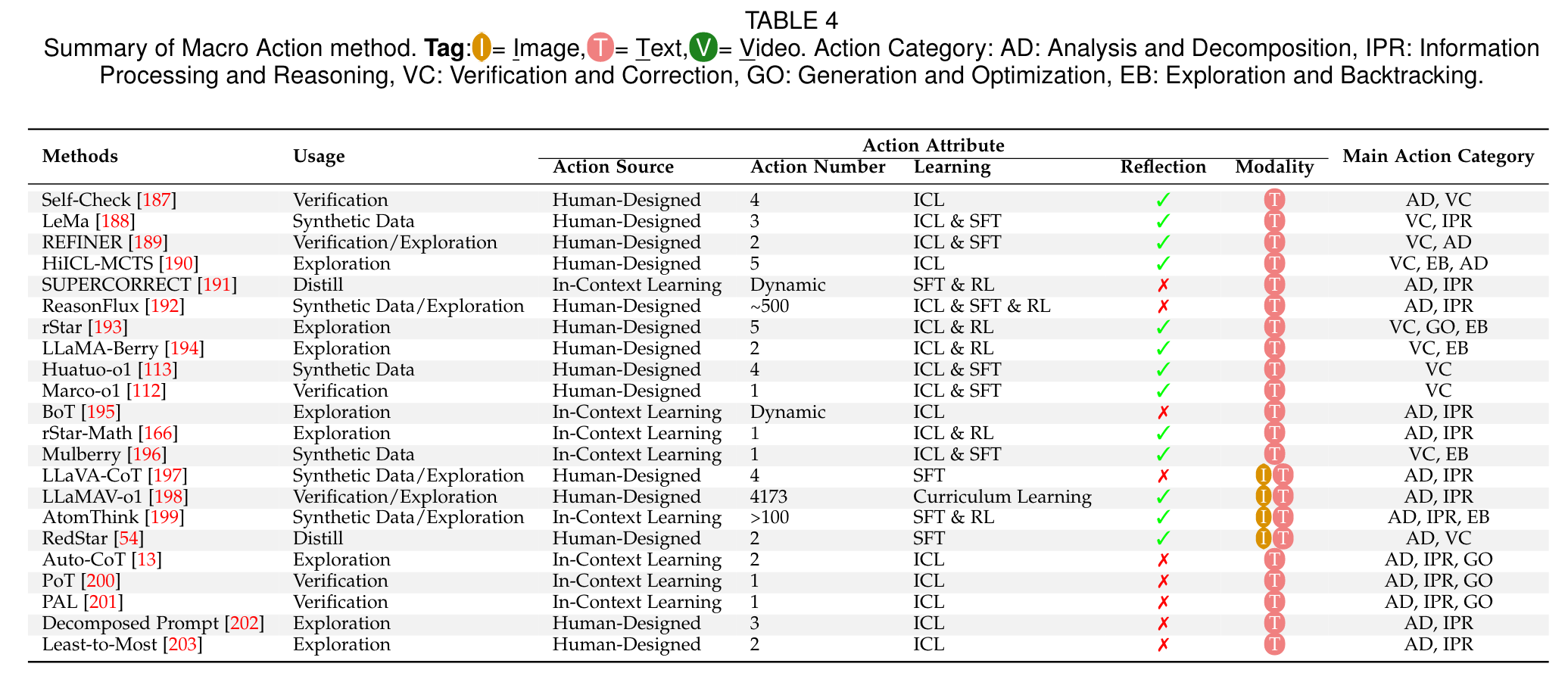
Macro Action
Reinforcement Fine-Tuning
Reinforcement Fine-Tuning (RFT) is an innovative technique recently introduced by OpenAI, designed to enable developers and engineers to fine-tune existing models for specific domains or complex tasks.
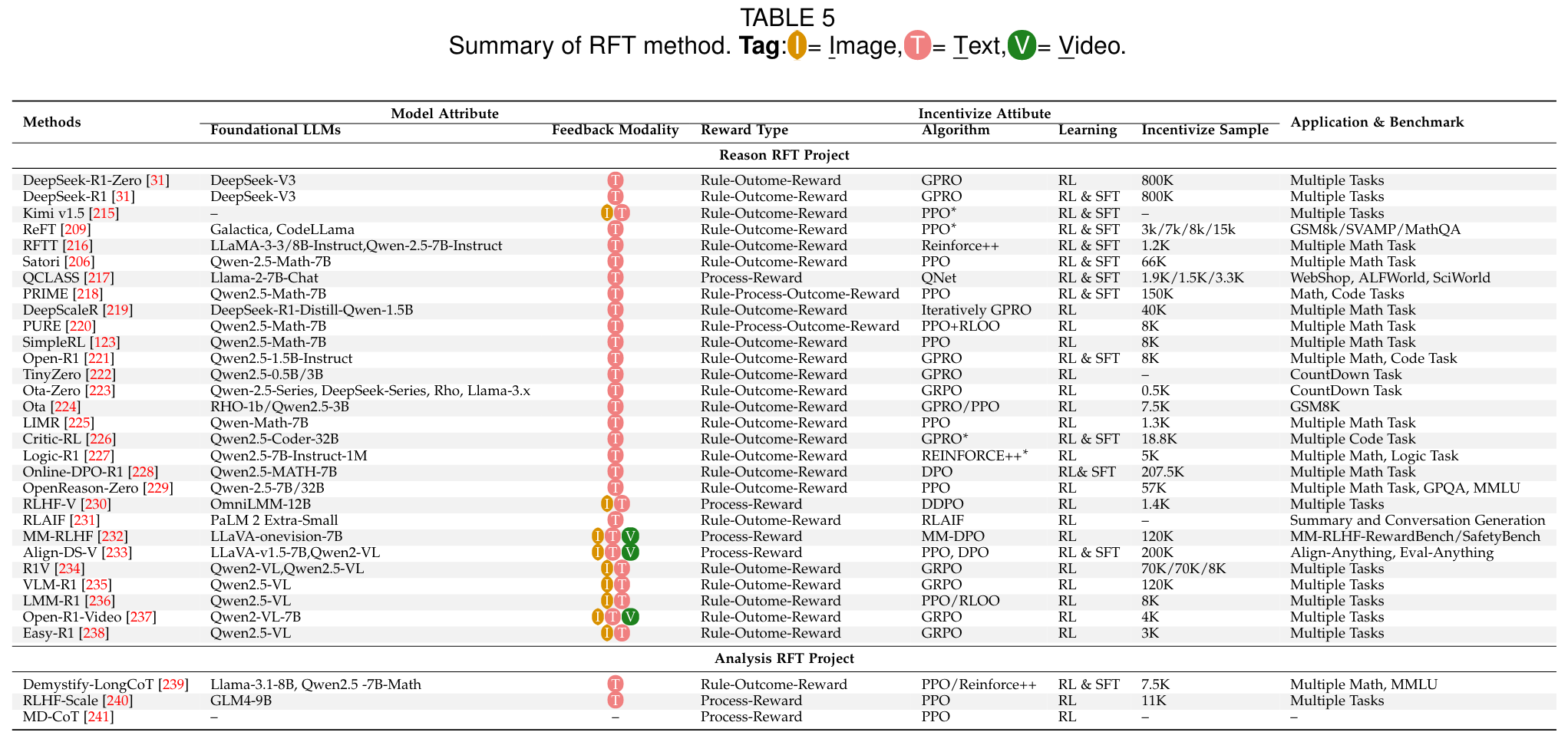
Key advantages include:
- Simplified Training Pipline: RL supervision streamlines data construction and training processes, eliminating the need for complex stepwise search mechanisms.
- Enhanced Scalability: Online RL training facilitates efficient scaling on large datasets, particularly for complex reasoning tasks.
- Emergent Properties: DeepSeek-R1 demonstrates unique emergent capabilities, such as Long-CoT reasoning, which are difficult to achieve through SFT alone.
RFT faces the following challenges:
- Unclear Mechanism behind Reasoning: The underlying mechanisms driving the reasoning improvements in DeepSeek-R1 remain poorly understood. For example, while DeepSeek-R1 exhibits emergent properties (e.g., “Emergent Length Increasing”, “Aha moments”), studies such as suggest that capabilities like Long-CoT might already exist in the base model, rather than solely emerging from RL training. Furthermore, performance gains observed in smaller models (e.g., Qwen-Math2B/7B) occur without noticeable “Aha moments”, complicating causal interpretations.
- Reward Model Saturation: Many existing RL algorithms face reward model saturation, typically manifested as exploration collapse after around 100 training steps. Although DeepSeek-R1 alleviates this issue through specialized reward formatting, methods like ReFT and Satori propose alternating sampling and SFT distillation to combat reward hacking and exploration collapse.
- Unstable Long-CoT Generation: Long reasoning chains generated by RFT are prone to instability, including context overflow, failure to return final answers, and sensitivity to reward shaping. For instance, methods like inadvertently introduce cosine reward functions, which degrade performance with increased iterations. O1-Prune uses post-hoc length pruning techniques (via RL/SFT) to stabilize outputs.
Future directions for RFT may include several exciting and innovative advancements, such as:
- Efficient and Stable RL Frameworks
- Scaling RFT
- Controlling Long-CoT Stability
- Theoretical and Empirical Analysis
推理LLM的一个关键挑战是快速思考的功能的丧失,这会导致效率低下时,当简单的任务需要不必要的深层推理时。与人类在快速(系统1)和慢速(系统2)思考之间的流畅切换不同,当前的推理LLM难以维持这种平衡。虽然推理LLMS确保有意和彻底的推理,但快速思维的系统依靠先验知识来快速响应。
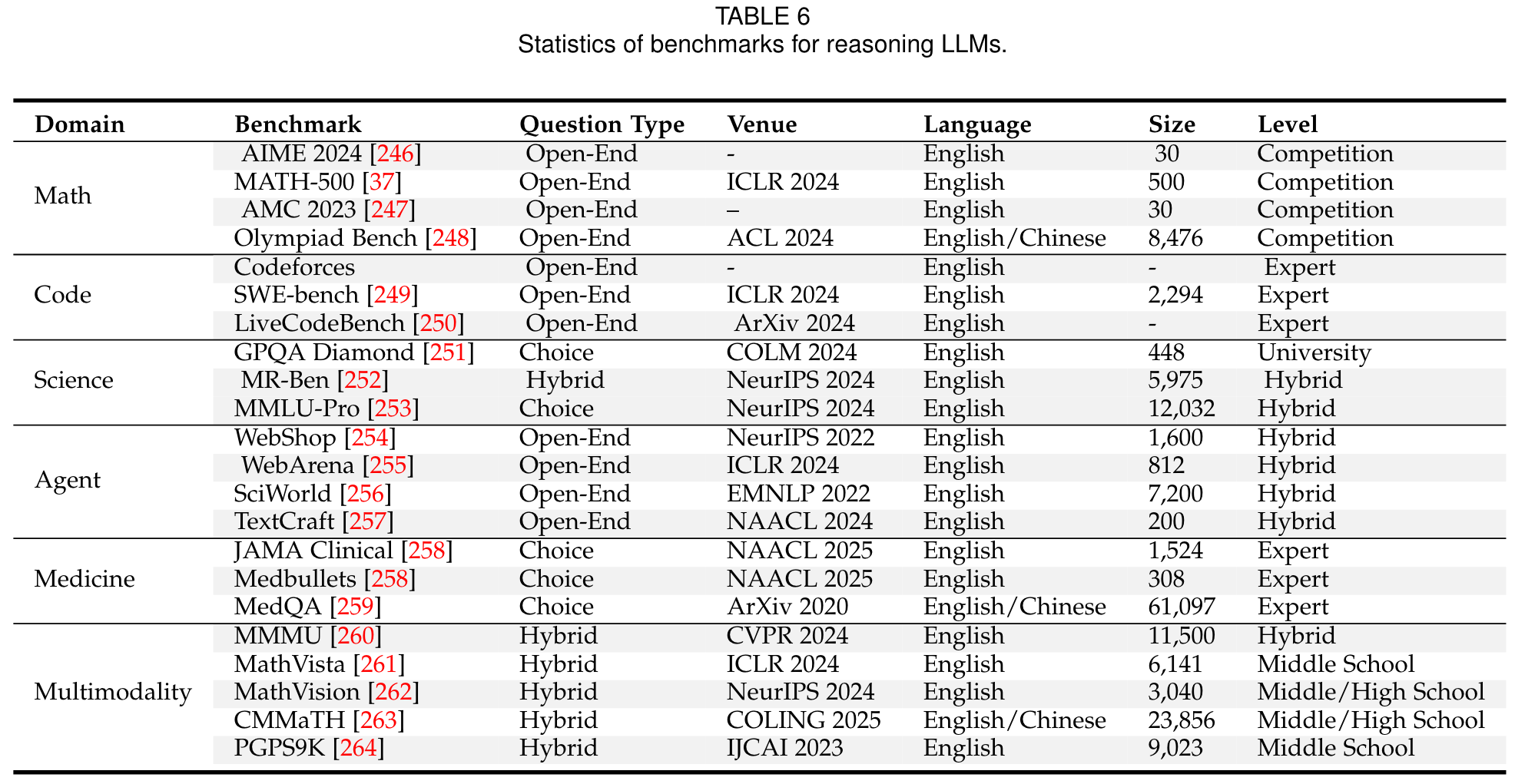
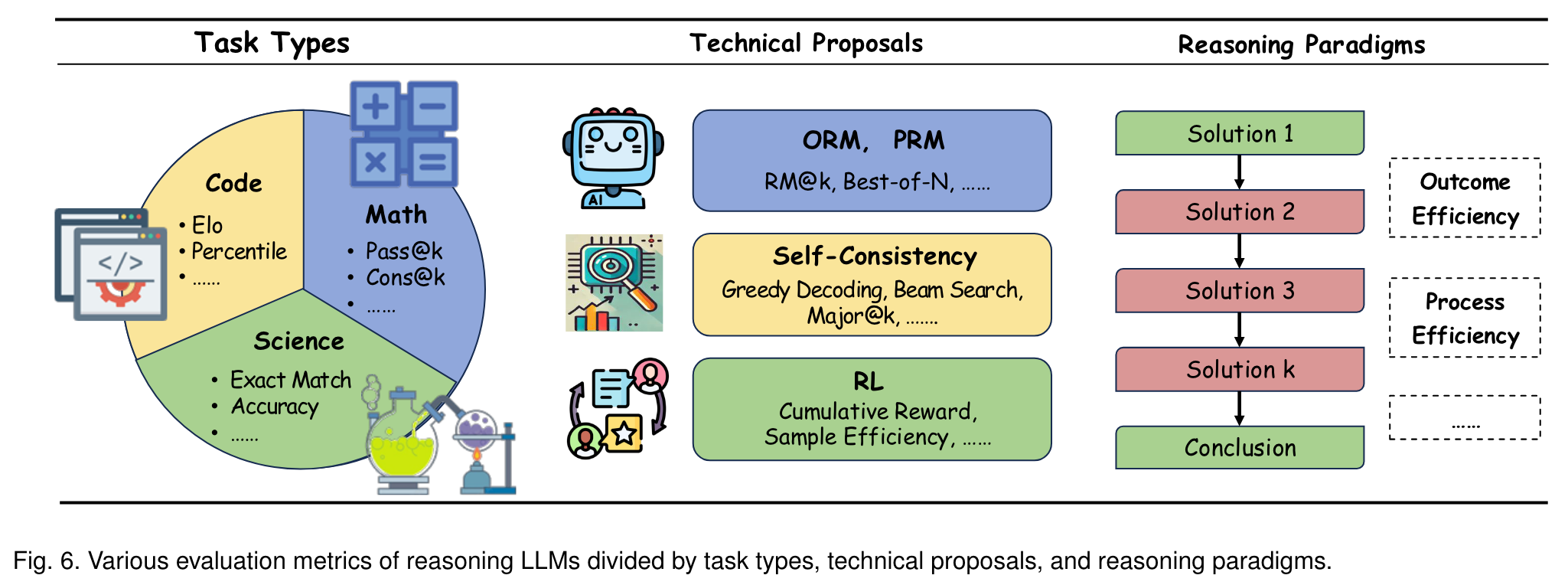
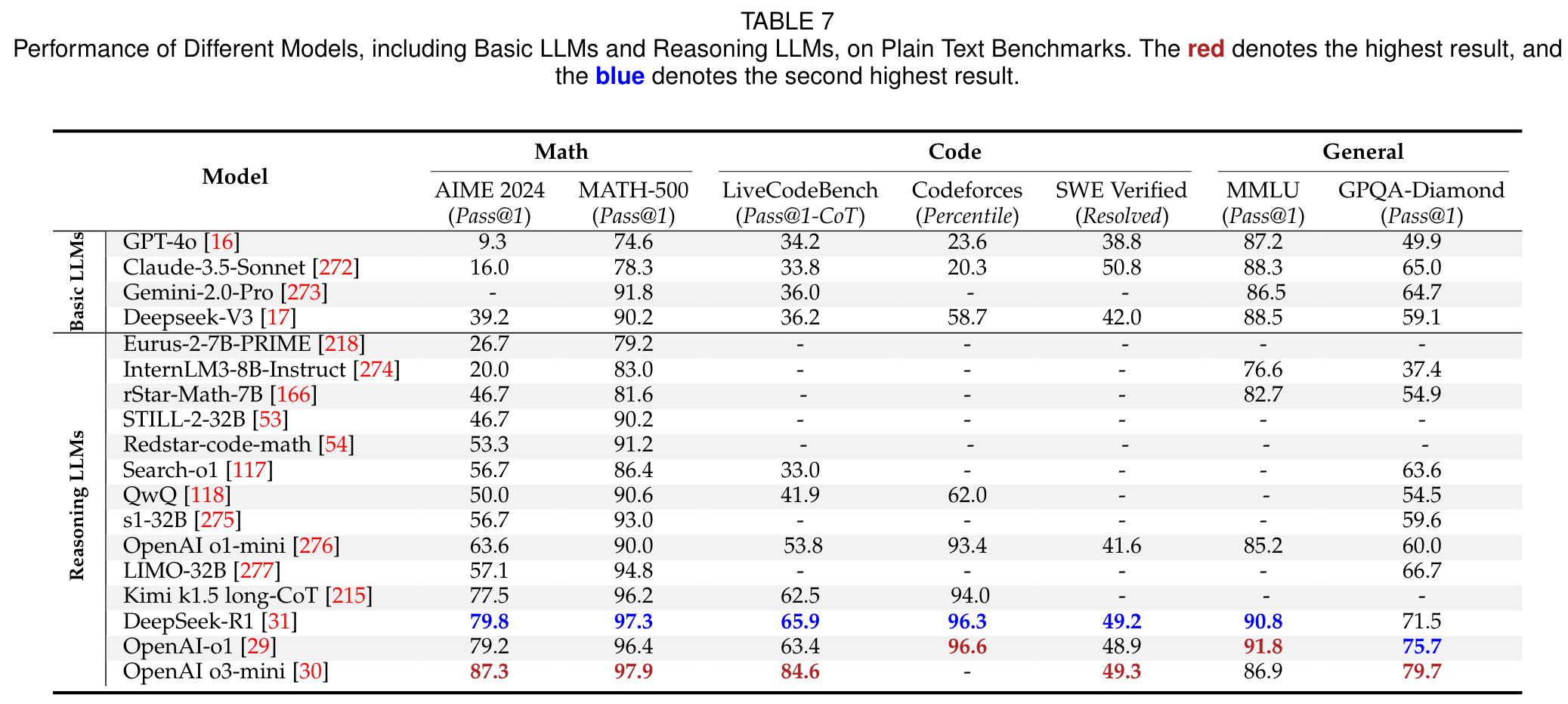
Benckmarks
🤖ChatGPT
ChapGPT
1. 论文的创新之处与独特性:
这篇论文《From System 1 to System 2: A Survey of Reasoning Large Language Models》在自然语言处理和人工智能领域具有以下显著的创新点和独特性:
(1) 系统化的“从System 1到System 2”框架
论文通过引入双系统认知理论(System 1和System 2),将人类的快速直觉式决策(System 1)与深度分析型推理(System 2)映射到大语言模型(LLMs)的能力演化中。这种框架有效地解释了从基础LLMs到推理LLMs的技术进步,并明确了构建“慢思考”推理能力的核心挑战。
(2) 对推理LLMs的核心技术方法的全面综述
论文从五个关键方法(结构搜索、奖励建模、自我改进、宏观动作、强化微调)深入剖析了推理LLMs的构建过程,提供了清晰的技术路线图。这种细粒度的分析不仅展示了当前的研究进展,还揭示了各方法的优缺点及适用场景。
(3) 推理LLMs的性能评估与基准分析
论文系统总结了推理LLMs在数学、代码生成、科学推理等多个领域的主流基准测试和评价指标,并对比了不同模型(如GPT-4o、DeepSeek-R1、OpenAI o1/o3)的性能。这种全面的基准分析为后续研究者提供了清晰的对比基准。
(4) 未来方向的展望
论文提出了多个具有前瞻性的研究方向,包括高效推理LLMs的开发、快慢思维协同系统、多模态推理、多语言推理,以及神经-符号系统的深度融合。这些方向具有较强的学术价值和实际应用潜力。
2. 论文中存在的问题及改进建议:
(1) 对System 1与System 2的边界定义不够清晰
尽管论文强调了“从System 1到System 2”的转变,但在技术实现层面上,对何时需要从快速决策转向深度推理缺乏明确的划分标准。这种模糊性可能导致模型在简单任务中过度推理或在复杂任务中推理不足。
改进建议:
- 引入任务复杂度的动态评估机制,通过模型在推理过程中的不确定性水平(如置信度分布)来动态切换System 1和System 2。
- 开发快慢思维切换的统一框架,结合强化学习与监督学习进行联合优化。
(2) 推理LLMs的效率问题被低估
论文提到推理LLMs在长推理链上的性能优势,但忽略了其高计算成本和时间延迟的问题。尤其是在实时应用场景中,这种长推理链可能难以满足效率需求。
改进建议:
- 在推理链中引入早停机制,即当模型的中间推理结果已经达到高置信度时,终止进一步推理。
- 探索轻量级的推理模型(如3B或7B参数规模)如何通过知识蒸馏或高效微调实现类似的推理性能。
(3) 多模态推理的研究深度不足
虽然论文提到了多模态推理的重要性,但对如何在视觉、文本和其他模态间进行深度推理整合的技术细节讨论较少。
改进建议:
- 针对多模态推理任务,提出跨模态的统一表示框架,结合视觉Transformer和文本Transformer进行联合建模。
- 引入多模态推理的专用基准,如科学实验设计或复杂工程问题,以测试模型的跨模态推理能力。
3. 基于论文的内容和研究结果,提出的创新点或研究路径:
(1) 创新点1:快慢思维协同推理系统
开发一个融合快思维(System 1)和慢思维(System 2)的动态协同推理框架,使模型能够根据任务复杂度和推理需求自适应地切换推理模式。
(2) 创新点2:高效推理LLMs的压缩与优化
探索如何通过参数压缩、知识蒸馏和奖励建模优化,构建轻量级但性能接近大型推理LLMs的高效推理模型。
(3) 创新点3:多模态推理的层次化结构
设计一个层次化的多模态推理框架,结合视觉、文本和符号推理能力,解决复杂的跨模态任务(如医学诊断、科学实验设计)。
4. 为新的研究路径制定的研究方案:
研究路径1:快慢思维协同推理系统
研究方法:
- 任务复杂度评估:设计任务复杂度评估指标(如置信度分布、推理路径长度),用于动态切换快慢思维模式。
- 快慢思维切换机制:结合强化学习和监督学习,训练模型在简单任务中快速决策,在复杂任务中调用慢推理模块。
- 模块化推理框架:开发一个可扩展的模块化框架,其中快思维模块负责快速生成初步答案,慢思维模块进行深度验证和调整。
研究步骤:
- 数据准备:构建包含简单任务(如基础数学问题)和复杂任务(如多步逻辑推理)的混合数据集。
- 模型训练:基于Transformer架构,训练快慢思维模块,并通过联合优化实现两者的协同工作。
- 实验评估:在多种基准测试(如GSM8K、Codeforces)上验证模型性能,并评估其效率。
期望成果:
- 快慢思维协同模型在复杂任务中性能优于单一推理模式模型,同时在简单任务中保持高效。
- 提供一种普适的快慢思维切换机制,适用于多种任务场景。
研究路径2:高效推理LLMs的压缩与优化
研究方法:
- 知识蒸馏:将大型推理LLMs的能力迁移到轻量级模型(如7B或3B参数规模)。
- 奖励建模优化:通过奖励建模引导轻量级模型的推理路径选择,提升其推理效率。
- 参数压缩:结合剪枝和量化技术,进一步降低模型的计算成本。
研究步骤:
- 蒸馏数据集构建:使用大型推理LLMs生成高质量的推理路径作为蒸馏数据。
- 蒸馏训练:训练轻量级模型模仿大型模型的推理能力。
- 参数优化:应用剪枝和量化技术,优化模型的存储和计算效率。
期望成果:
- 轻量级模型的推理性能接近大型模型,同时计算成本降低50%以上。
- 提供一套高效推理LLMs的通用优化方法。
研究路径3:多模态推理的层次化结构
研究方法:
- 跨模态表示学习:开发统一的跨模态表示框架,将视觉、文本和符号信息映射到共享的语义空间。
- 层次化推理结构:设计多层推理模块,底层处理单模态推理,高层进行跨模态信息融合与推理。
- 多模态奖励建模:针对多模态任务设计奖励函数,引导模型在推理过程中更好地融合不同模态的信息。
研究步骤:
- 数据准备:收集多模态推理任务数据集(如医学影像诊断、科学实验设计)。
- 模型训练:基于Transformer架构,训练多模态推理模型,并通过奖励建模进行优化。
- 实验评估:在多模态基准测试(如MathVision、MathVista)上验证模型性能。
期望成果:
- 提出一种通用的多模态推理框架,显著提升模型在跨模态任务中的性能。
- 为多模态推理任务提供新的技术路径和基准数据集。
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!