目录
Resource Info Paper https://arxiv.org/abs/2502.09601 Code & Data / Public arXiv Date 2025.03.18
Summary Overview
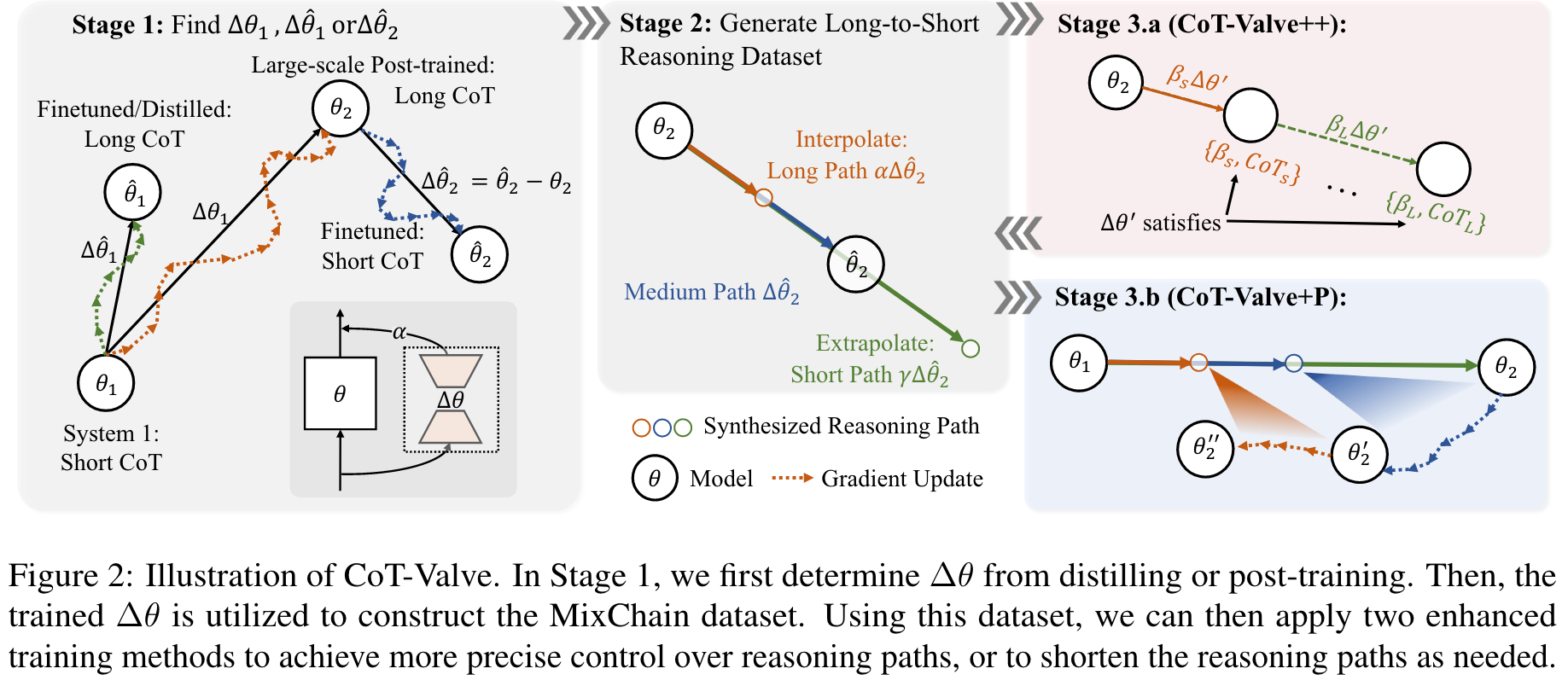
通过观察到,在简单任务下可以压缩思维链长度但是在复杂任务上不是这样的,作者探索了仅使用一个模型来弹性控制推理路径长度的可行性,从而根据任务难度动态地减少了推理模型的推理开销 (CoT-Valve)。我们构建具有从长到短的连锁的数据集,以解决相同的问题,并探索了 CoT-Valve 的两个增强策略:(1)一种精确的长度可压缩的COT调整方法,以及(2)渐进的链长度压缩方法。
Main Content
Thus, a long reasoning path is still essential, while maintaining the ability to compress reasoning paths for simpler questions is equally important.

We choose to incorporate this update direction by LoRA, enabling it to function as an additional branch that facilitates easy modulation of intensity while imposing minimal extra parameters on the model.
Contributions
- Cot-Valve: Enables elastic control of length for CoT within the parameter space, allowing a single model to generate CoT from short to long.
- MixChain Dataset: A dataset with reasoning paths of varying lengths for each question.
- Improved Tuning & Progressive Compression: Refines the direction tuning process based on MixChain and introduces progressive compression for inference efficiency.
- Performance & Controllability: Achieves controllable reasoning generation and state-of-the-art results for compressed CoT.
Metics:
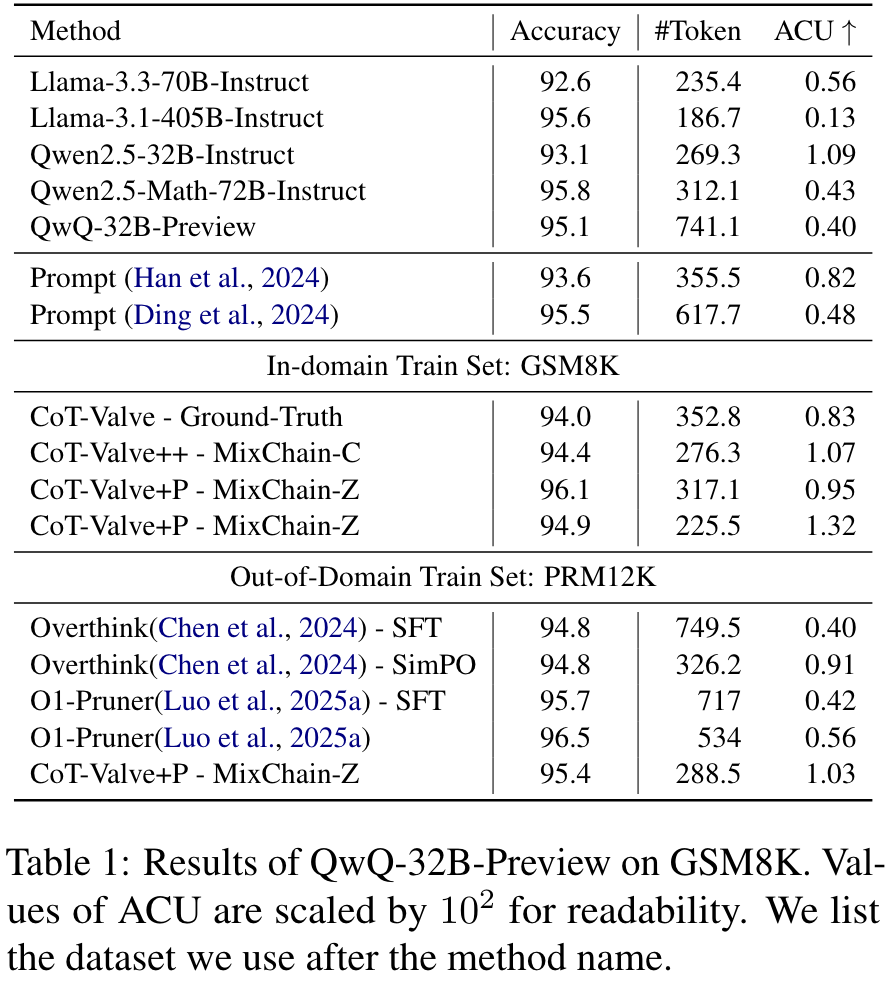
- Accuracy per Computation Unit(ACU), to better capture this balance and evaluate model efficiency.
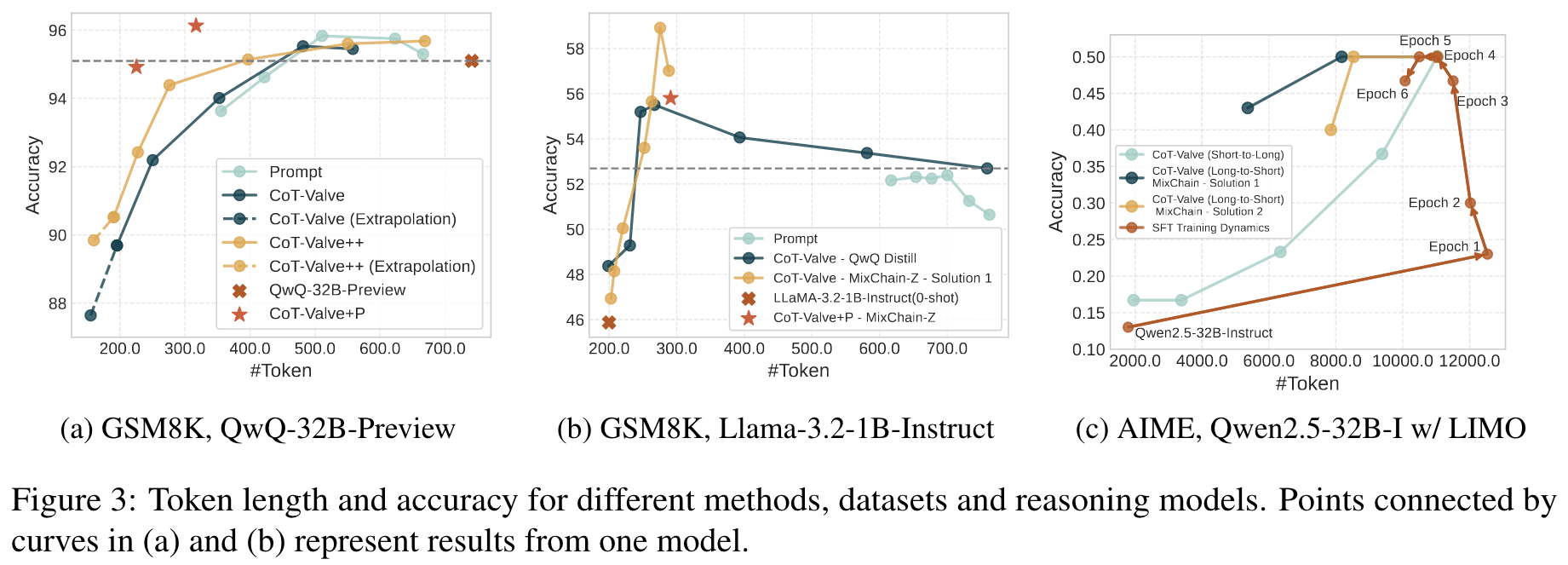
Observations
- Longer reasoning chains are not always the best on simple datasets.
- Some reasoning chains are difficult for the model to learn, especially for small LLMs.
🤖
-
论文的创新之处与独特性:
- 动态推理路径长度控制:论文提出了“CoT-Valve”,通过在参数空间中识别并操控一个方向向量,实现了对推理路径长度的动态控制。这种方法允许一个模型同时生成长链和短链推理路径,避免了传统方法中需要单独训练多种模型的资源浪费。
- 基于LoRA的参数高效调整:采用LoRA(低秩适配)技术对参数进行调整,以最小化模型额外参数开销的同时实现推理路径长度的可控性。这种创新方式使得在推理过程中对链长的调节变得更加灵活。
- MixChain数据集的构建:论文构建了一个MixChain数据集,其中每个问题都包含从长到短的多种推理路径。这种数据集设计为模型提供了更丰富的训练样本,支持更精确的链长控制。
- 性能与推理效率的平衡:通过实验表明,适度压缩推理链可以在保持高准确率的同时显著减少推理的计算成本,特别是在简单任务中短链推理甚至优于长链推理。
-
论文中存在的问题及改进建议:
- 对复杂任务的适用性不足:论文主要在简单数学任务(如GSM8K)上验证了方法的有效性,但在更复杂的推理任务(如AIME24)中,短链推理的表现不如长链推理。改进建议:进一步优化短链推理的生成策略,例如通过引入更细粒度的推理步骤选择机制,确保关键步骤不会被压缩掉。
- 对方向向量的解释性不足:虽然论文提出了通过参数空间方向向量控制链长的概念,但对该向量的具体性质及其与推理路径长度的关系缺乏深入的理论分析。改进建议:结合可视化或数学分析,探索方向向量的几何意义及其对推理过程的影响。
- 对训练数据质量的依赖:MixChain数据集的构建依赖于模型生成的推理路径质量,而这些路径可能包含噪声或不一致性。改进建议:引入自动化验证机制或人类专家标注,提升训练数据的质量。
- 缺乏多模态任务验证:论文仅在文本推理任务中进行了实验,未探索方法在多模态任务(如视觉推理)中的应用潜力。改进建议:在多模态任务上验证CoT-Valve的性能,如图像理解或视觉问答。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 创新点1:探索更细粒度的推理路径压缩机制,例如通过动态评估每一步推理对最终答案的贡献,智能跳过冗余步骤。
- 创新点2:将CoT-Valve方法扩展到多模态推理任务,研究推理路径长度控制在视觉-语言任务中的适用性。
- 创新点3:结合强化学习,优化方向向量的选择过程,使得模型能够根据任务难度自适应调整推理路径长度。
- 创新点4:开发基于MixChain的半监督学习框架,利用未标注数据进一步提升模型的推理能力。
-
为新的研究路径制定的研究方案:
-
研究路径1:细粒度推理路径压缩机制
- 研究方法:基于信息论或贝叶斯网络,计算每一步推理对最终答案的贡献度;设计动态跳步机制,仅保留高贡献度的推理步骤。
- 研究步骤:
- 构建一个包含详细推理路径标注的高质量数据集。
- 开发基于信息增益的推理步骤贡献度评估算法。
- 通过实验验证动态跳步机制对推理效率和准确率的影响。
- 期望成果:提出一种细粒度推理路径压缩算法,在复杂任务中显著减少推理链长度,同时保持高准确率。
-
研究路径2:多模态推理任务中的CoT-Valve扩展
- 研究方法:将CoT-Valve方法应用于视觉-语言任务(如图像描述生成或视觉问答),探索推理路径长度控制在多模态任务中的效果。
- 研究步骤:
- 收集并构建多模态推理任务数据集(如包含图像和对应问题的标注数据)。
- 对视觉-语言模型进行LoRA微调,加入CoT-Valve机制。
- 比较不同链长的推理路径对多模态任务性能的影响。
- 期望成果:验证CoT-Valve在多模态任务中的有效性,并提出适用于多模态任务的推理路径长度控制方法。
-
研究路径3:结合强化学习优化方向向量
- 研究方法:引入强化学习框架,通过奖励函数优化方向向量的选择,使得模型能够根据任务难度自适应调整推理路径长度。
- 研究步骤:
- 设计奖励函数,综合考虑推理路径长度、准确率和计算成本。
- 利用强化学习算法(如PPO或DDPG)优化方向向量。
- 在多种任务上测试模型的自适应能力。
- 期望成果:开发一种基于强化学习的自适应推理路径长度控制方法,显著提升模型在不同任务上的推理效率。
-
研究路径4:基于MixChain的半监督学习框架
- 研究方法:利用MixChain数据集中的长链和短链样本,通过伪标注和一致性正则化,提升未标注数据的利用率。
- 研究步骤:
- 构建包含未标注问题的大规模数据集。
- 设计伪标注生成策略,利用现有模型生成长链和短链推理路径。
- 引入一致性正则化,确保模型对同一问题的长链和短链推理路径生成一致答案。
- 期望成果:提出一种基于MixChain的半监督学习框架,显著提升模型在低资源场景下的推理能力。
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!