目录
Resource Info Paper https://arxiv.org/abs/2501.12599 Code & Data / Public arXiv Date 2025.03.19
Summary Overview
Kimi k1.5 技术报告,主要聚焦于其中使用的 Reinforcement Learning 技术。
Main Content
扩展强化学习(RL)为人工智能的持续改进开辟了一条新的轴线,大型语言模型(LLM)有望通过学习探索奖励来扩展其训练数据。
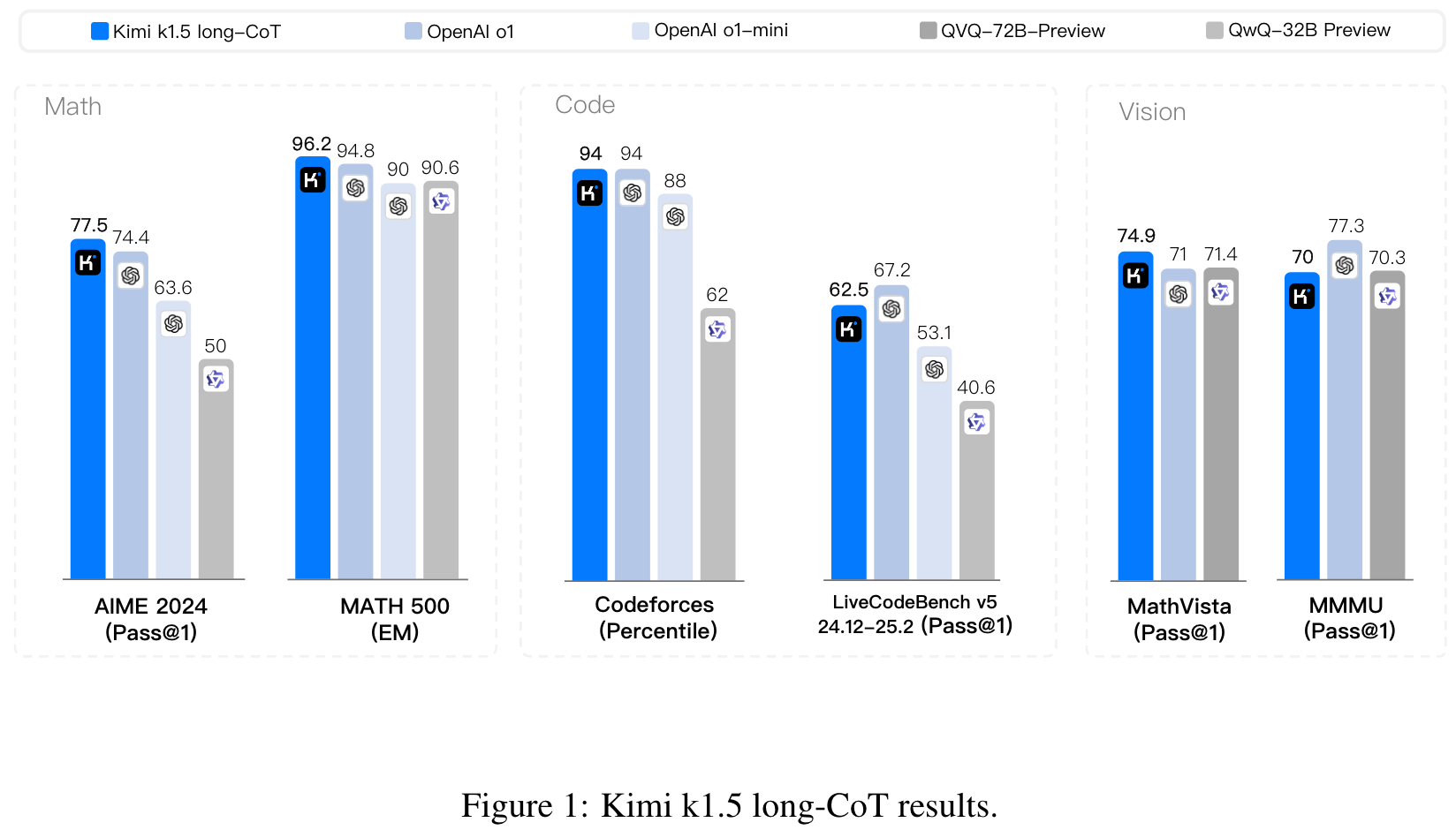
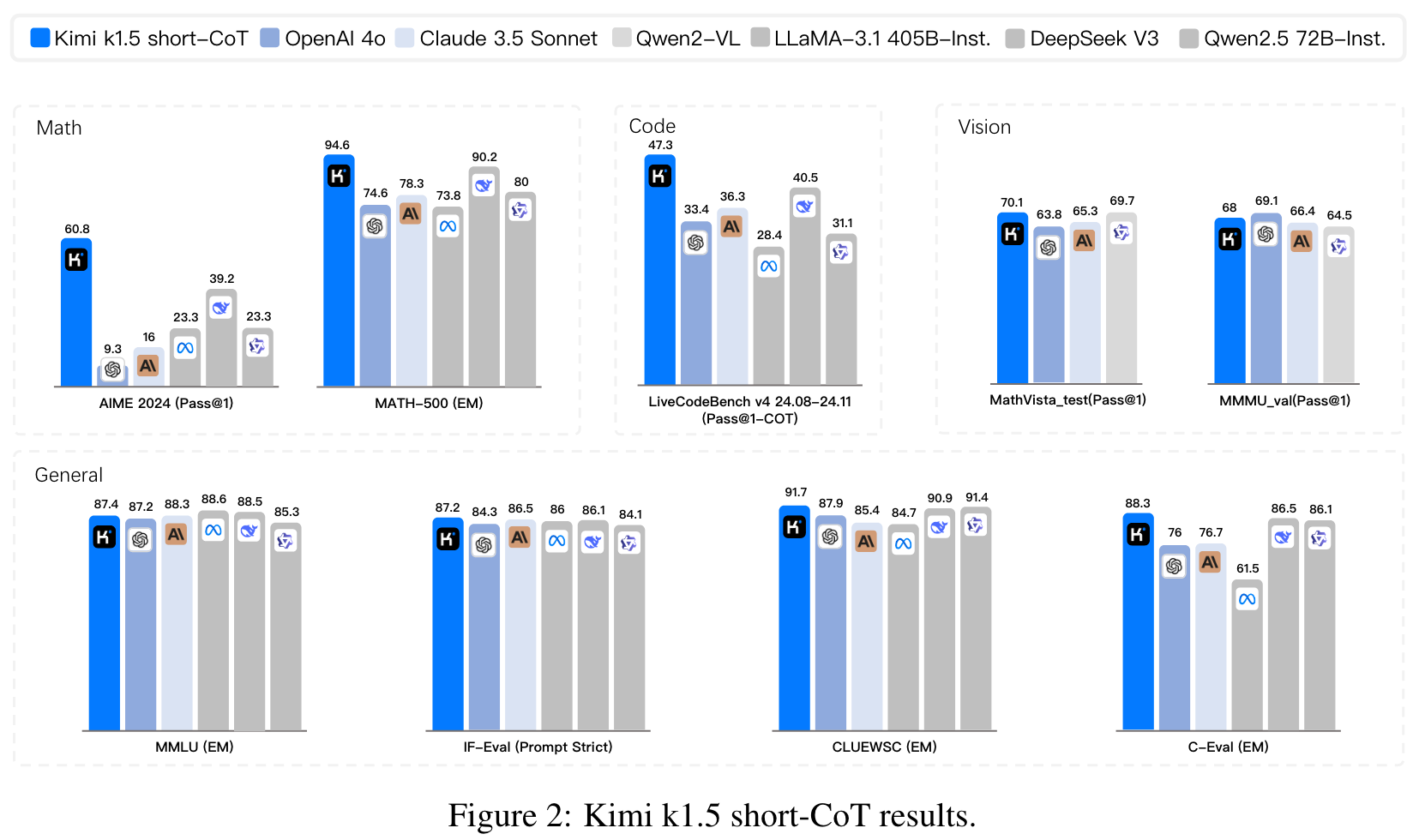
Using RL with LLMs, the models learns to explore with rewards and thus is not limited to a pre-existing static dataset.
Key ingredients:
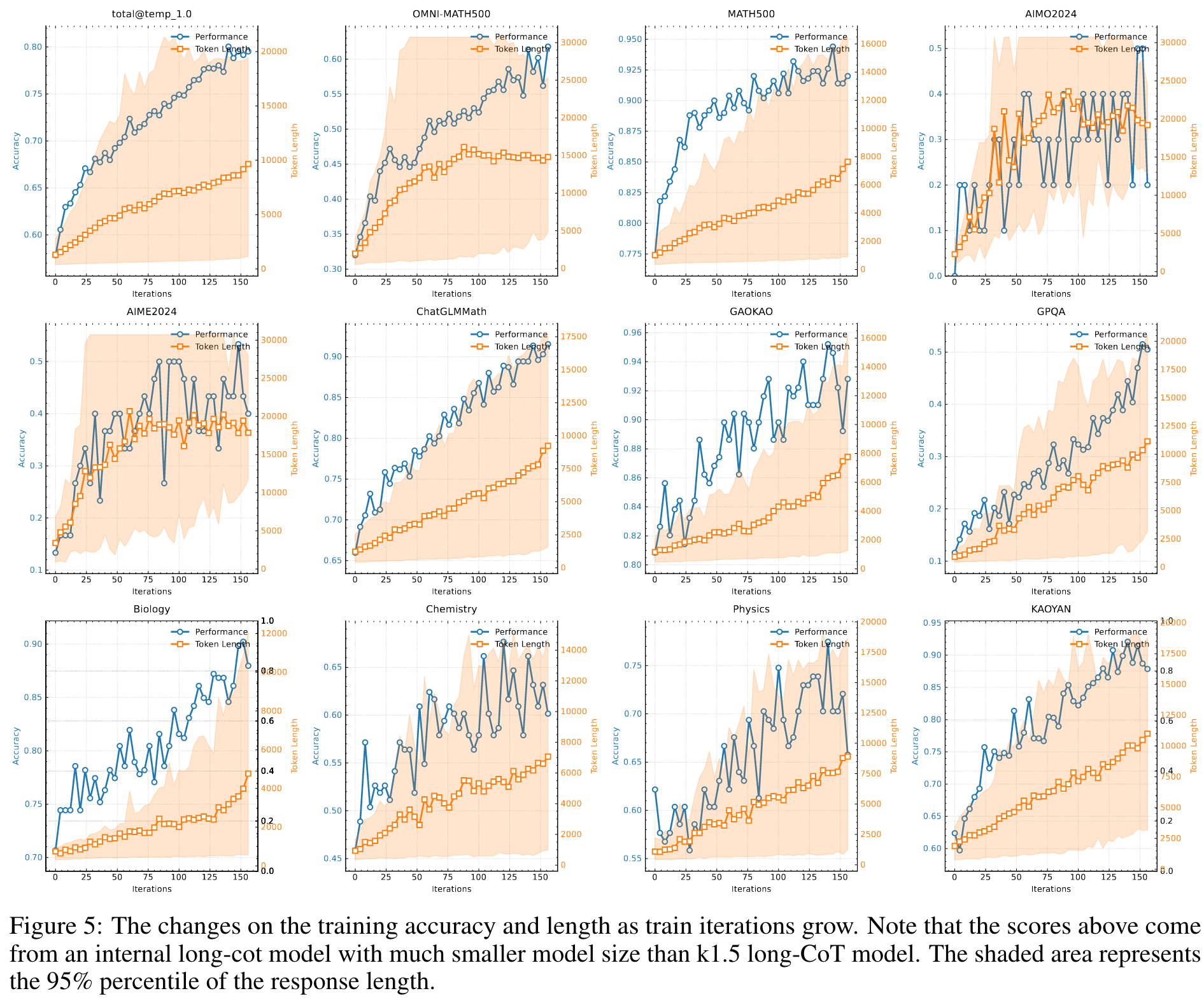
- Long context scaling: 观察到持续的性能提升伴随着增长的 context length.
- Improved policy optimization: We derive a formulation of RL with long-CoT and employ a variant of online mirror descent for robust policy optimization. This algorithm is further improved by our effective sampling strategy, length penalty, and optimization of the data recipe.
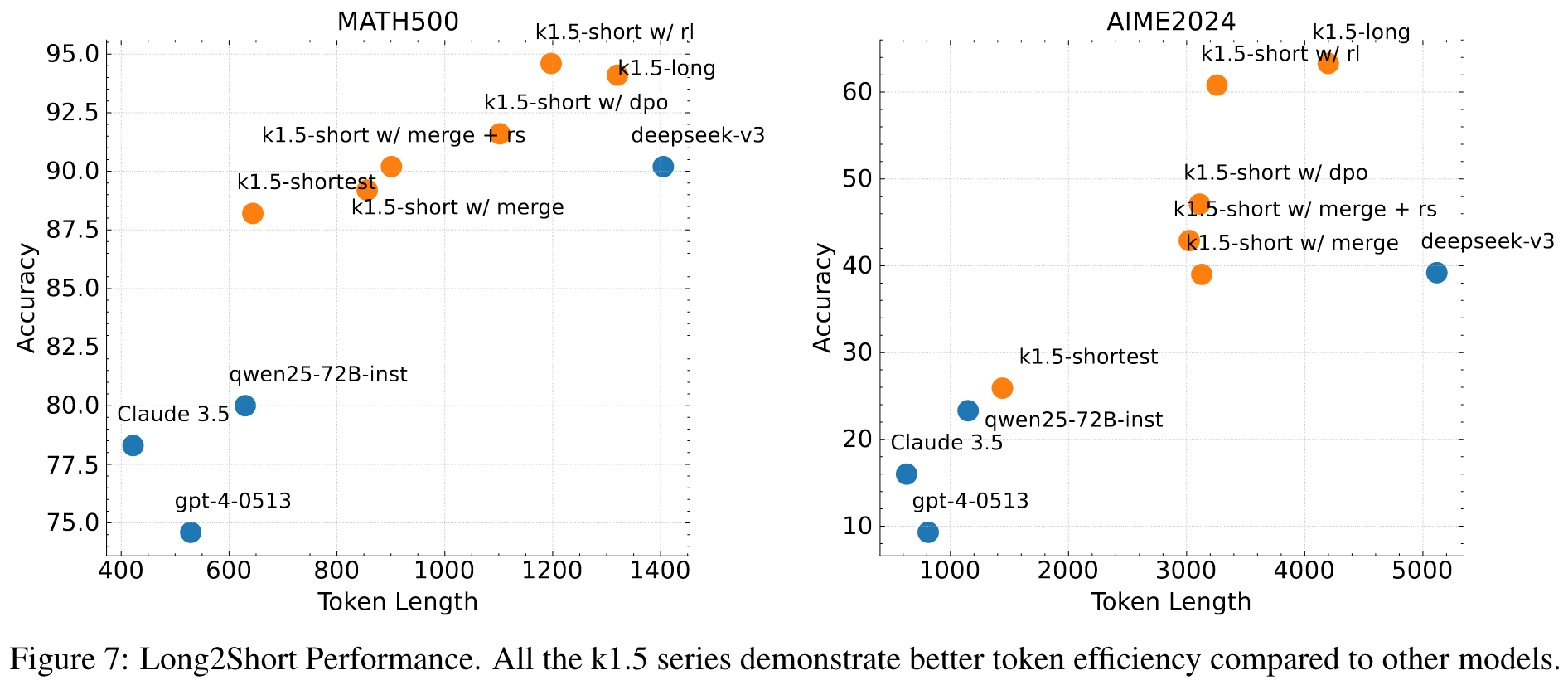
Moreover, we present effective long2short methods that use long-CoT techniques to improve short-CoT models. Specifically, our approaches include applying length penalty with long-CoT activations and model merging.
Stages: pretraining, vanilla supervised fine-tuning (SFT), long-CoT supervised fine-tuning, and reinforcement learning (RL).
Three key properties define a high-quality RL prompt set:
- Diverse Coverage
- Balanced Difficulty: The prompt set should include a well-distributed range of easy, moderate, and difficult questions to facilitate gradual learning and prevent overfitting to specific complexity levels.
- Accurate Evaluability: Prompts should allow objective and reliable assessment by verifiers, ensuring that model performance is measured based on correct reasoning rather than superficial patterns or random guess.
经验观察表明,一些复杂的推理问题可能有相对简单和容易猜测的答案,从而导致假阳性验证--即模型通过错误的推理过程得出正确答案。为解决这一问题,我们排除了容易出现此类错误的问题,如多项选择题、真/假题和基于证明的问题。此外,对于一般的答题任务,我们提出了一种简单而有效的方法来识别和删除易被破解的提示。具体来说,我们会提示模型猜测可能的答案,而无需任何 CoT 推理步骤。如果模型在 N 次尝试内预测出正确答案,则认为该提示太容易被破解,并将其删除。我们发现,设置 N = 8 可以删除大部分易被破解的提示。
Human-like reasoning:
- planning: the model systematically outlines steps before execution;
- evaluation: critical assessment of intermediate steps;
- reflection: enable the modle to reconsider and refine its approach;
- exploration: encourage consideration of alternative solutions;
Reinforcement Learning
When solvinig problem , thoughts are auto-regressively sampled, followed by the final answer are auto-regressively sampled, followed by the final answer to denote this sampling procedure.
Rather than explicitly constructing a search tree and implementing a planning algorithm, we could potentially train a model to approximate this process.
Reward
- For verifiable problems, the reward is directly determined by predefined criteria or rules.
- For problems with free-form ground truth, we train a reward model that predicts if the answer matches the ground truth.
Optimize the policy:
Policy Optimization
surrogate loss:
gradient
Length Penalty
This length-based reward is then added to the original reward with a weighting parameter.
In our preliminary experiments, length penalty may slow down training during the initial phases. To alleviate this issue, we propose to gradually warm up the length penalty during training. Sepcifically, we employ standard policy optimization without length penalty,followed by a constant lenght penalty for the rest of training.
Sampling Strategies
First, the RL training data we collect naturally come with different difficulty labels. Second, because the RL training process samples the same problem multiple times, we can also track the success rate for each individual problem as a metric of difficulty.
- Curriculum Sampling: We start by training on easier tasks and gradually progress to more challenging ones.
- Prioritized Sampling: We track the success rate for each problem and sample problems proportional to , so that problems with lower success rates receive higher sampling probabilities. This directs the model's efforts toward its weakest areas, leading to faster learning and better overall performance.
Long2short: Context Compression for Short-CoT Models
Though long-CoT models achieve strong performance, it consumes more test-time tokens compared to standard short-CoT LLMs. However, it is possible to transfer the thinking priors from long-CoT models to short-CoT models so that performance can be improved even with limited test-time token budgets.
- Model Merging: we merge the two models by simply averaging their weights.
- Shortest Rejection Sampling
- DPO
- Long2short RL
RL Infrastructure
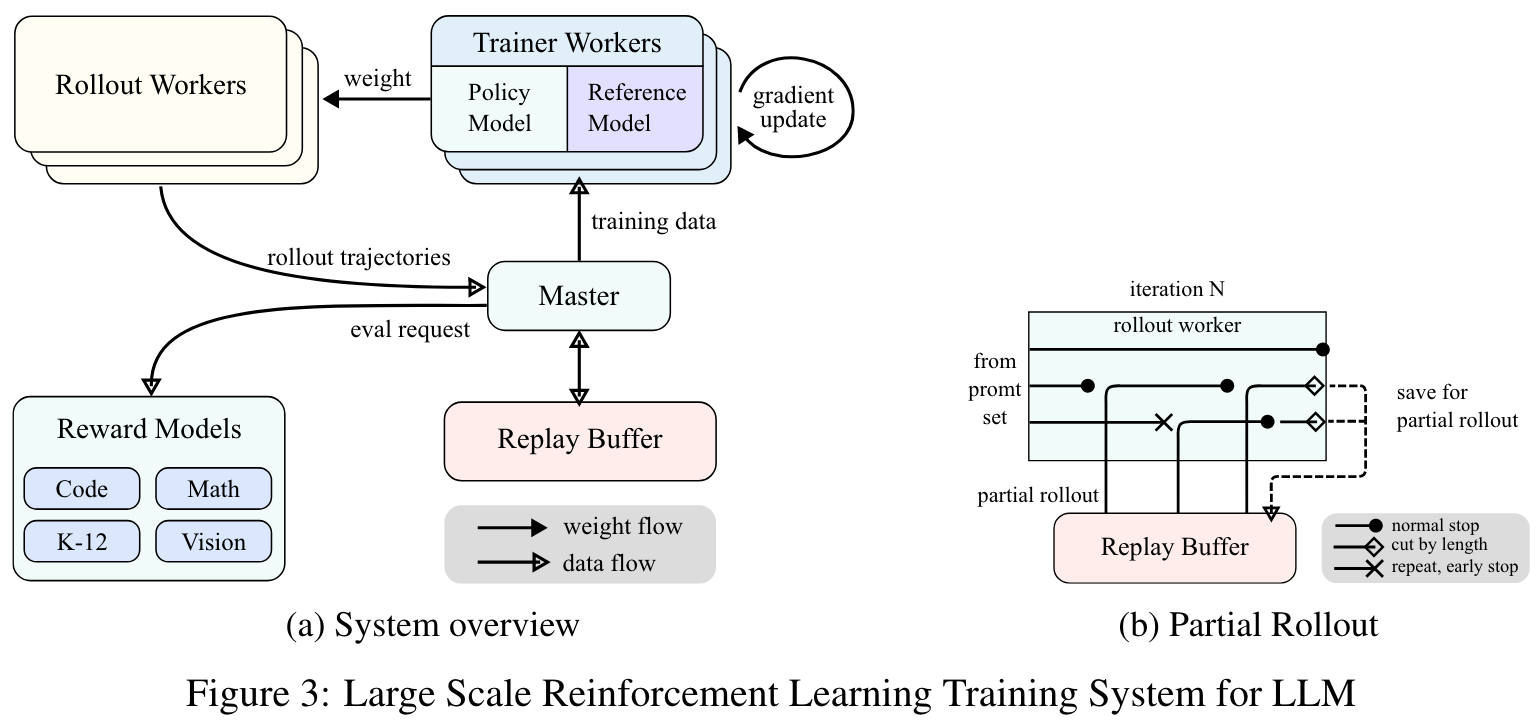
Rollout Phase & Training Phase: During the rollout phase, rollout workers, coordinated by a central master, generate rollout trajectories by interacting with the model, producing sequences of responses to various inputs. In the subsequent training phase, trainer workers access these experiences to update the model's weights. This cyclical process allows the model to continuously learn from its actions, adjusting its strategies over time to enhance performance.
Partial Rollouts for Long CoT RL: Partial rollouts is a key technique that effectively addresses the challenge of handling long-CoT features by managing the rollouts of both long and short trajectories. It ensures that no single lengthy trajectory monopolizes the system's resources. Moreover, since the rollout workers operate asynchronously, when some are engaged with long trajectories, others can independently process new, shorter rollout tasks. The implementation of partial rollouts also offers repeat detection. The system identifies repeated sequences in the generated content and terminates them early, reducing unnecessary computation while maintaining output quality. Detected repetitions can be assigned additional penalties, effectively discouraging redundant content generation in the prompt set.
Hybird Deployment of Training and Inference
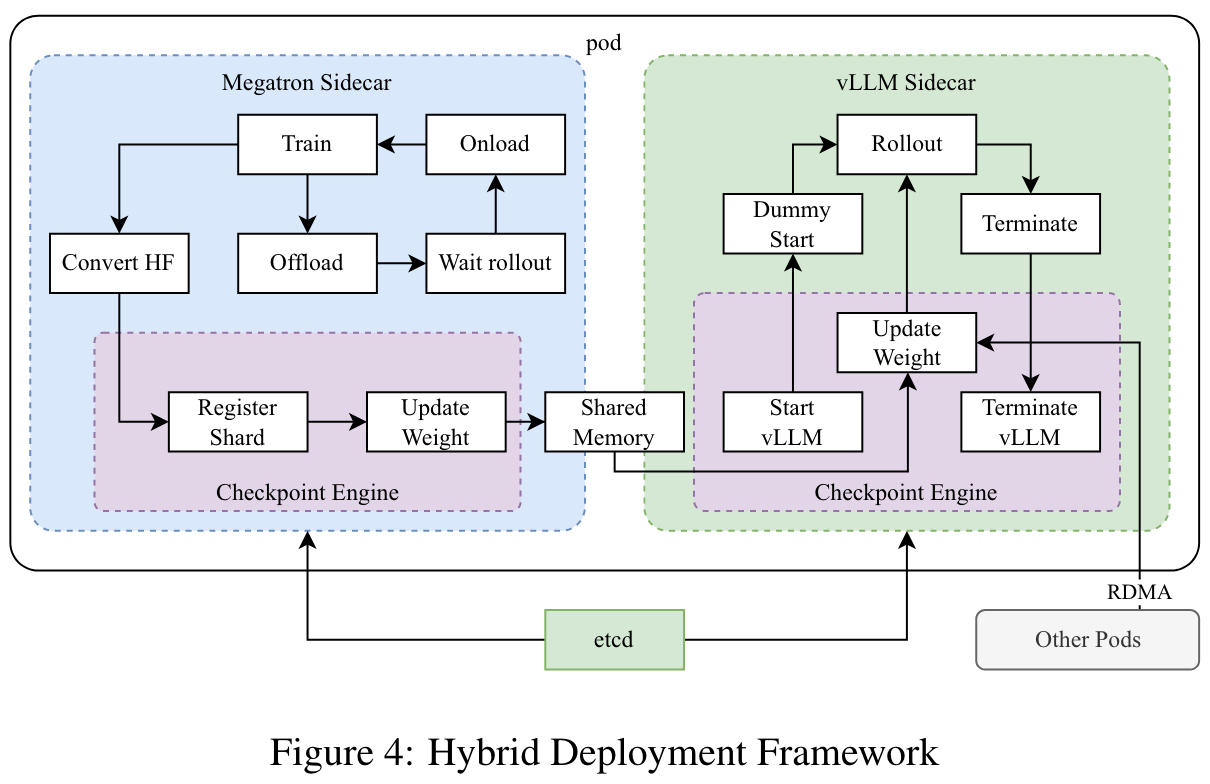
- Training Phase: At the outset, Megatron and vLLM are executed within separate containers, encapsulated by a shim process known as checkpoint-engine. Megatron commences the training procedure. After the training is completed, Megatron offloads the GPU memory and prepares to transfer current weights to vLLM.
- Inference Phase: Following Megatron's offloading, vLLM starts with dummy model weights and updates them with the latest ones transferred from Megatron via Mooncake. Upon completion of the rollout, the checkpoint-engine halts all vLLM processes.
- Subsequent Training Phase: Once the memory allocated to vLLM is released, Megatron onloads the memory and initiates another round of training.
Results
🤖
-
论文的创新之处与独特性:
- 长上下文扩展与RL优化的结合:论文提出了一种将长上下文扩展(128k tokens)与强化学习(RL)结合的训练方法。这种方法通过部分回溯采样(Partial Rollouts)大幅提高了训练效率,同时展示了长上下文对复杂推理任务的显著提升效果。这种方法避免了传统强化学习中对复杂规划算法(如蒙特卡洛树搜索)的依赖,简化了框架设计。
- 多模态数据融合与推理能力提升:Kimi k1.5 模型通过多模态数据(文本与视觉)的联合训练,在跨模态推理任务(如 MathVista 和 MMMU)上达到了最先进的性能。其多模态数据策略涵盖了图像-文本交错数据、OCR数据和知识型数据,特别是对视觉推理能力的强化值得关注。
- 长到短(Long2Short)方法:论文提出了长到短的迁移方法,通过将长链式推理(Long-CoT)的思维过程压缩到短链式推理(Short-CoT)中,显著提高了短推理模型的性能,同时保持了较高的推理效率。这种方法包括模型融合、最短拒绝采样、DPO(直接偏好优化)和RL微调等多种技术。
- 简化的强化学习优化框架:论文采用了一种基于在线镜像下降(Online Mirror Descent)的简化强化学习优化方法,并结合长度惩罚策略,有效控制了模型的“过度思考”现象,优化了推理效率。
-
论文中存在的问题及改进建议:
- 长上下文的硬件依赖性:长上下文扩展(128k tokens)对硬件资源的需求极高,尤其是在推理阶段可能导致实际应用的受限。改进建议:探索更高效的上下文压缩方法,例如基于注意力稀疏化的技术,或开发更轻量级的推理框架。
- 多模态数据的质量控制与偏差:虽然论文强调了多模态数据的质量控制,但具体的偏差消除策略(如视觉数据中语言偏差的处理)未详尽描述。改进建议:引入更多自动化的偏差检测与修正机制,例如通过对不同模态的特征分布进行对比分析,确保模型在多模态任务中的泛化能力。
- 长到短方法的泛化性不足:长到短(Long2Short)方法在短链式推理任务上表现优异,但其对更复杂的跨模态任务(如视觉-文本推理)的泛化性尚未充分验证。改进建议:在实验中增加更多高复杂度的跨模态任务,验证长到短方法的适用范围。
- 奖励模型的透明性和鲁棒性:论文中提到的奖励模型在某些任务中可能存在主观性和不一致性。改进建议:开发更透明的奖励模型评估标准,例如通过引入多种验证机制(如多样性评分和一致性评分)提高奖励模型的鲁棒性。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 创新点1:基于稀疏注意力的长上下文高效推理框架
- 研究背景:长上下文扩展虽然提升了推理能力,但对计算资源的需求极高。可以引入稀疏注意力机制减少计算开销。
- 创新点2:多模态联合推理中的模态对齐优化
- 研究背景:多模态数据中存在模态间信息不一致的问题,例如视觉和文本信息的语义不匹配。可以探索更高效的模态对齐方法。
- 创新点3:动态上下文压缩与推理优化
- 研究背景:长上下文模型在推理时可能包含大量冗余信息。可以研究动态上下文压缩方法,根据任务需求实时调整上下文长度。
- 创新点1:基于稀疏注意力的长上下文高效推理框架
-
为新的研究路径制定的研究方案:
-
研究方案1:基于稀疏注意力的长上下文高效推理框架
- 方法:设计一种基于稀疏注意力的Transformer结构,通过局部注意力窗口和全局关键节点的结合,减少计算复杂度。
- 步骤:
- 设计稀疏注意力机制,确保在长上下文中捕捉关键信息。
- 在现有的长上下文任务上(如MATH-500和AIME 2024)进行实验,验证性能和效率。
- 比较稀疏注意力模型与全局注意力模型的性能差异,特别是在推理时间和准确率上的表现。
- 期望成果:在保持推理准确率的前提下,将计算开销降低50%以上,为长上下文模型的实际应用提供更可行的解决方案。
-
研究方案2:多模态联合推理中的模态对齐优化
- 方法:引入一种基于对比学习的模态对齐方法,通过对齐视觉和文本特征空间,提升多模态推理能力。
- 步骤:
- 构建一个大规模的多模态对齐数据集,确保视觉和文本信息的语义一致性。
- 设计对比学习损失函数,使视觉和文本特征在共享空间中最大程度对齐。
- 在多模态基准(如MathVista和MMMU)上进行评估,验证对齐方法的有效性。
- 期望成果:在多模态任务上提升5%以上的准确率,同时增强模型对跨模态任务的泛化能力。
-
研究方案3:动态上下文压缩与推理优化
- 方法:开发一种动态上下文压缩算法,根据任务复杂度和上下文相关性实时调整输入长度。
- 步骤:
- 设计上下文压缩模块,结合注意力权重和语义相似度选择关键上下文片段。
- 在长上下文任务上进行实验,分析动态压缩对推理效率和准确率的影响。
- 将动态压缩算法与长到短方法结合,进一步提升短链式推理任务的性能。
- 期望成果:在不显著降低准确率的情况下,将推理时间缩短30%以上,并提高短链式推理任务的整体效率。
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!