目录
Resource Info Paper https://arxiv.org/abs/2504.01296 Code & Data https://github.com/UCSB-NLP-Chang/ThinkPrune Public arXiv Date 2025.05.08
Summary Overview
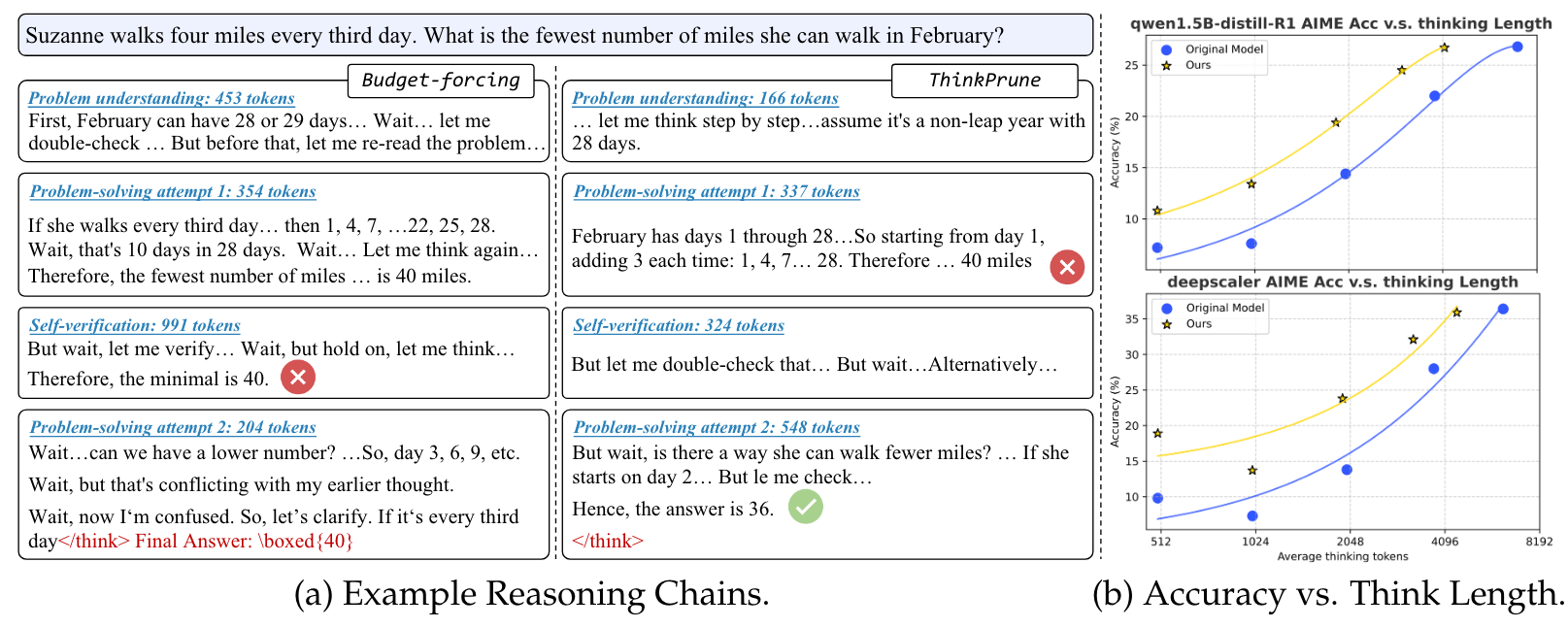
文章介绍了一个使用强化学习来减少 Reasoning Model 输出 CoT 长度的方法 THINKPRUNE。方法思想比较简单,通过设定 token 限制,任何没有完成的 response 和超过长度限制的都将被丢弃,从而获得的 reward 为0。
Main Content
其实在实际的实现中,只管截断即可。因为长度超出了自然就不会获得最终的答案,reward 自动变成0。
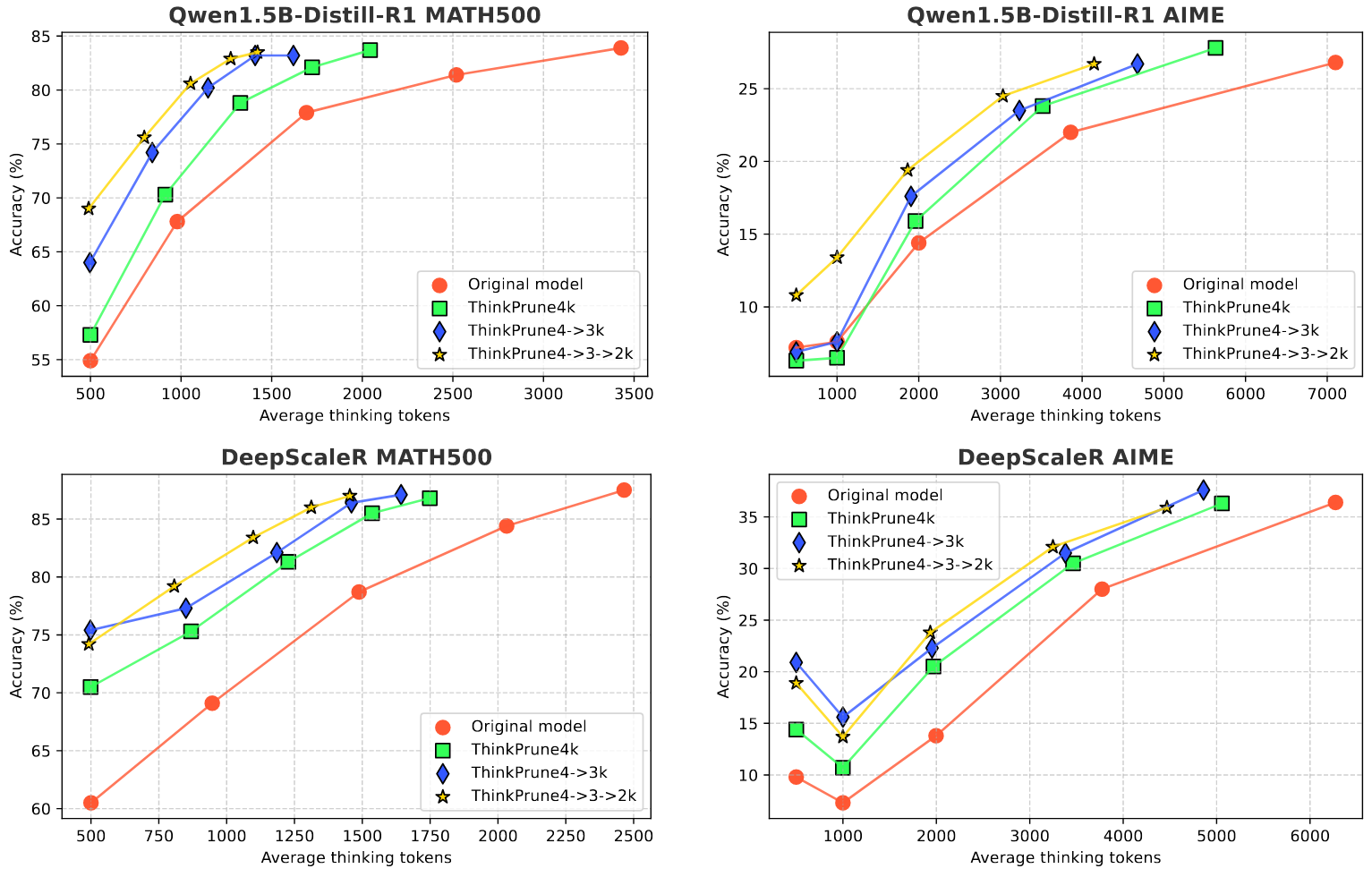
作者在文中还提出了迭代式的训练方法,即 token 限制从 4K变为3K再最后变为2K。


Behavior Analaysis
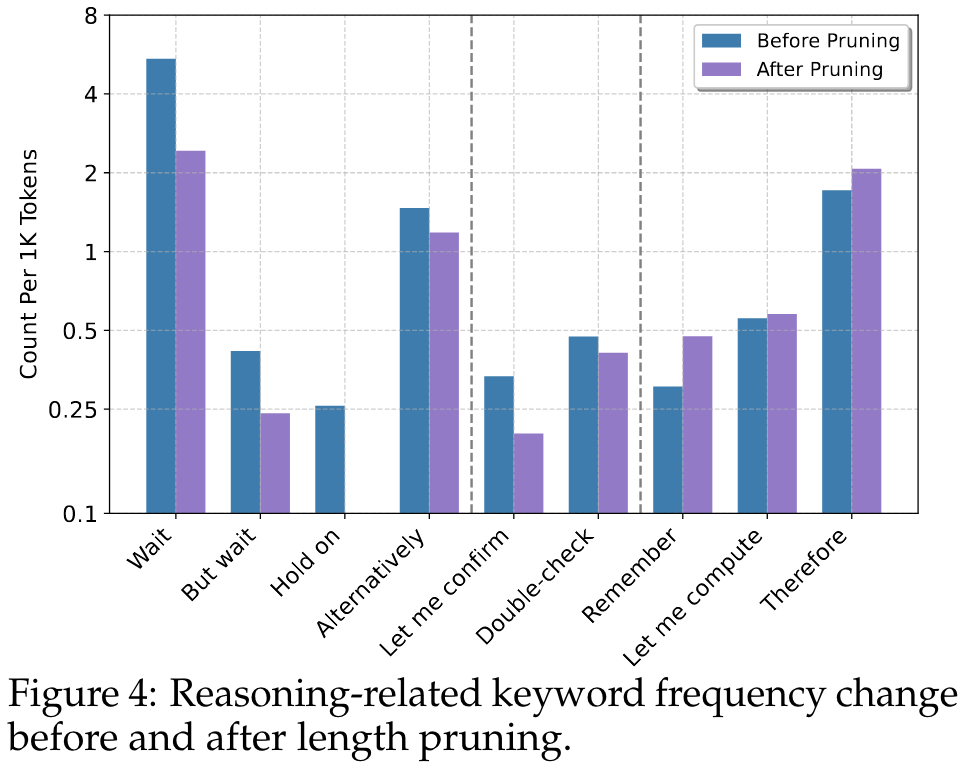
The left section contains phrases that signal hesitations or self-corrections, which we find under go a significant drop in frequency after pruning. This indicates that the model would hesitate less.
The middle section contains phrases that signal self-verification, which undergo a slight drop in frequency after pruning. This indicates that the model would sometimes skip the self-verification steps, which may sacrifice a little bit of accuracy, to save the token length. Finally, the right section contains phrases that signal core computation and reasoning, which have a slight increase in frequency despite the overall reduction in length. This indicates that the model would maintain the reasoning process, because that is the core process that contributes to the final solution.
🤖
- 论文的创新之处与独特性:
这篇论文的主要创新点在于解决LLM在推理过程中的"过度思考"问题,同时保持强大的推理性能。具体来说:
- 论文提出了一种方法来减少长链思维(long Chain-of-Thought)LLM中的冗余推理,同时保持其推理能力。这解决了现有强化学习训练的LLM虽然推理能力强但推理过程过长的问题。
- 论文表明,通过标准的强化学习训练管道,无需改变奖励函数,就能显著减少过度思考问题。这是一个重要发现,因为它表明可以在不牺牲性能的情况下提高推理效率。
- 研究指出,通过强化学习与可验证奖励(RLVR)训练的LLM(如OpenAI-o3和DeepSeek-R1)虽然展示了更深入的思考行为(如广泛探索和可行性检查),但这些行为往往导致推理过程变得冗长,增加了推理成本。
从中我们可以学到的关键点是:
- 强化学习在提升LLM推理能力方面的潜力
- 推理效率与推理深度之间的权衡关系
- 如何在不牺牲性能的情况下优化LLM的推理过程
- 论文中存在的问题及改进建议:
基于提供的上下文,可能存在的问题包括:
- 论文可能缺乏对不同任务类型下方法有效性的全面评估。改进建议:扩大评估范围,包括更多样化的任务类型,特别是那些需要不同深度推理的任务。
- 上下文中没有明确说明如何定量衡量"过度思考"。改进建议:建立更客观的指标来衡量推理过程中的冗余度,例如通过分析推理步骤的信息增益。
- 可能缺乏与其他压缩或优化方法的比较。改进建议:将提出的方法与其他推理优化技术(如知识蒸馏、剪枝等)进行比较,评估相对优势。
- 对于不同规模的模型,该方法的有效性可能有所不同。改进建议:研究方法在不同规模模型上的适用性,并提供相应的调整策略。
- 基于论文的内容和研究结果,提出的创新点或研究路径:
创新点1:自适应推理深度控制
- 开发一种机制,使LLM能够根据问题复杂度自动调整推理深度,简单问题使用简短推理,复杂问题保留深度思考。
创新点2:多粒度推理框架
- 设计一个分层推理框架,将推理过程分为高层规划和低层执行两个阶段,高层规划决定整体推理策略,低层执行负责具体细节,从而减少冗余思考。
创新点3:推理路径优化
- 开发一种算法来识别和优化LLM推理路径中的冗余或循环模式,类似于程序优化中的死代码消除。
创新点4:混合推理模型
- 结合短链思维和长链思维的优势,训练一个能够在不同模式间切换的混合模型,根据任务需求灵活调整推理深度。
- 为新的研究路径制定的研究方案:
研究方案1:自适应推理深度控制
研究方法:
- 第一阶段:收集并标注不同复杂度问题的数据集,包括问题特征和最优推理深度
- 第二阶段:训练一个元控制器,学习预测给定问题所需的最佳推理深度
- 第三阶段:将元控制器与主LLM集成,实现动态推理深度调整
研究步骤:
- 构建包含不同复杂度问题的多样化数据集
- 为每个问题标注最优推理深度(可通过人工评估或自动化指标)
- 设计并训练元控制器,输入为问题特征,输出为推荐的推理深度
- 开发一种机制,使主LLM能够根据元控制器的建议调整推理过程
- 在多个基准测试上评估系统性能,特别关注推理效率与准确性的平衡
期望研究成果:
- 一个能够根据问题复杂度自动调整推理深度的LLM系统
- 与固定推理深度相比,在推理效率上提高30%以上,同时保持或提高准确率
- 关于问题特征与最优推理深度关系的新见解
研究方案2:多粒度推理框架
研究方法:
- 设计一个两阶段推理框架,包括高层规划和低层执行
- 通过强化学习训练高层规划器,学习如何分解问题并分配资源
- 优化低层执行器,专注于高效完成具体推理步骤
研究步骤:
- 设计高层规划器架构,负责问题分解和推理策略制定
- 设计低层执行器架构,负责执行具体推理步骤
- 开发两个组件间的通信协议和接口
- 使用强化学习训练高层规划器,奖励函数结合准确性和效率
- 优化低层执行器,专注于特定推理步骤的高效执行
- 集成两个组件,形成完整的多粒度推理系统
- 在复杂推理任务上评估系统性能
期望研究成果:
- 一个新型的分层推理框架,能够更高效地处理复杂推理任务
- 相比传统方法,在保持准确率的同时,推理步骤减少40%以上
- 关于如何最佳分解复杂推理问题的新方法论
研究方案3:推理路径优化
研究方法:
- 开发算法识别LLM推理过程中的冗余模式和循环
- 设计优化技术来压缩或消除这些冗余
- 结合程序分析和机器学习方法来自动化优化过程
研究步骤:
- 收集大量LLM推理轨迹数据,包括成功和失败的案例
- 开发算法来分析推理轨迹,识别常见的冗余模式和循环
- 设计基于规则的优化器,用于消除明显的冗余
- 训练机器学习模型来预测哪些推理步骤可能是冗余的
- 将规则和学习型优化器结合,创建混合推理路径优化系统
- 开发接口,允许优化器在LLM推理过程中实时干预
- 在多个推理任务上评估系统性能
期望研究成果:
- 一套能够识别和优化LLM推理路径的算法工具包
- 推理效率提升50%以上,同时保持或提高准确率
- 关于LLM推理中常见冗余模式的新见解,可用于改进模型训练
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!