目录
Resource Info Paper https://arxiv.org/abs/2310.12931 Code & Data https://github.com/eureka-research/Eureka Public ICLR Date 2025.06.30
Summary Overview
Large Language Models (LLMs) have excelled as high-level semantic planners for sequential decision-making tasks. However, harnessing them to learn complex low-level manipulation tasks, such as dexterous pen spinning, remains an open problem. We bridge this fundamental gap and present EUREKA, a human-level reward design algorithm powered by LLMs.
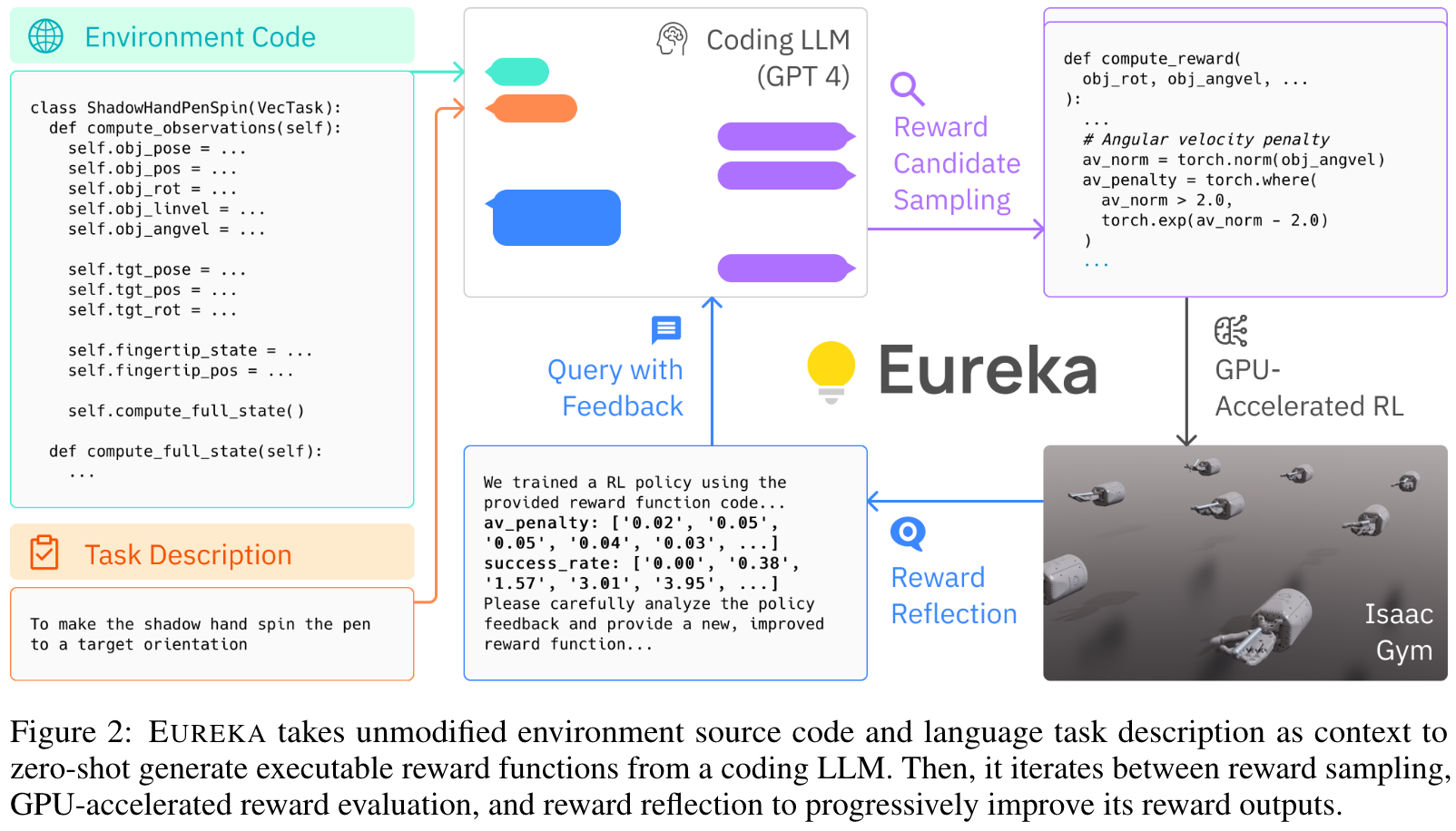
Evolution-driven Universal REward Kit for Agent (EUREKA), a novel reward design algorithm powered by coding LLMs with the following contributions:
- Achieves human-level performance on reward design
- Solves dexterous manipulation tasks that were previously not feasible by manual reward engineering
- Enable a new gradient-free in-context learning approach to reinforcement learning from human feedback (RLHF)
Main Content
Problem Setting and Definitions
The goal of reward design is to return a shaped reward function for a ground-truth reward function that may be difficult to optimize directly (e.g., sparse rewards); this ground-truth reward function may only be accessed via queries by the designer.
Definition 2.1. (Reward Design Problem (Singh et al., 2010)) A reward design problem (RDP) is a tuple where is the world model with state space , action space , and transition function . is the space of reward functions. is a learning algorithm that outputs a policy that optimizes reward in the resulting Markov Decision Process (MDP), . is the fitness function that produces a scalar evaluation of any policy, which may only be accessed via policy queries (i.e., evaluate the policy using the ground truth reward function).
In an RDP, the goal is to output a reward function such that the policy that optimizes achieves the highest fitness score .
Reward Generation Problem. In our problem setting, every component within a RDP is specified via code. Then, given a string that specifies the task, the objective of the reward generation problem is to output a reward function code such that is maximized.

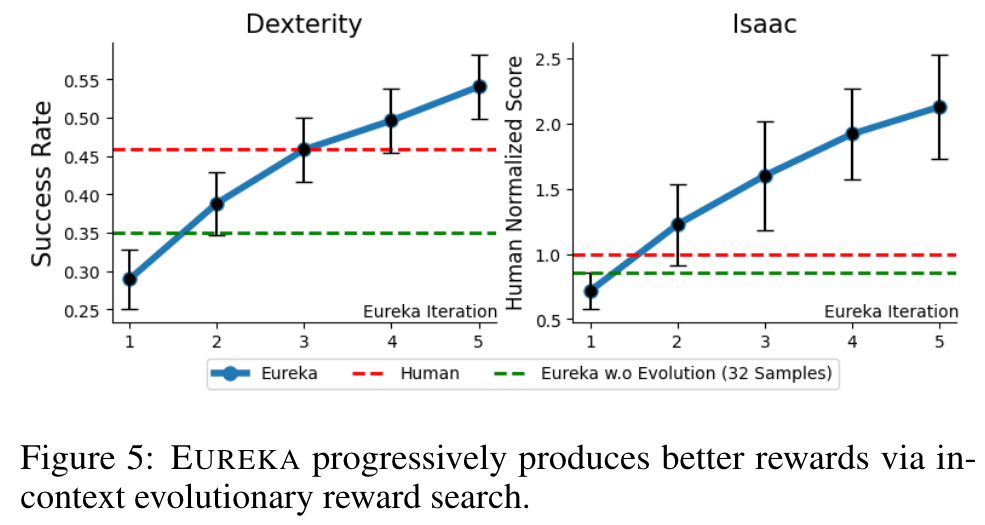
EUREKA outperforms human rewards.

EUREKA consistently improves over time.
🤖
-
论文的创新之处与独特性:
- 提出了EUREKA框架:EUREKA是一种基于编码大语言模型(LLMs)和进化搜索的新型奖励设计算法。其独特之处在于无需任务特定的提示或奖励模板,通过环境代码作为上下文,能够零样本生成可执行的奖励函数。这种方法显著减少了人工试错设计奖励的复杂性。
- 实现了人类级别的奖励生成能力:EUREKA在29个RL环境中表现优异,覆盖了10种不同的机器人形态。在83%的任务中,EUREKA生成的奖励超过了专家设计的奖励,平均改进幅度达52%。
- 解决复杂任务的能力:EUREKA首次实现了基于Shadow Hand的快速笔旋转任务,展示了其在高维度、复杂任务中的适应性。
- 引入奖励反思机制:通过奖励反思(reward reflection),EUREKA能够基于训练反馈动态改进奖励函数。这种机制为奖励设计提供了细粒度的优化信号。
- 支持人类反馈的强化学习:EUREKA能够结合人类提供的文本反馈生成更符合人类意图的奖励函数,为强化学习从人类反馈(RLHF)提供了一种无梯度的学习方法。
-
论文中存在的问题及改进建议:
- 依赖任务适合的评价函数:EUREKA需要一个明确的任务评价函数(fitness function),然而在一些开放式任务中,定义明确的评价函数可能较为困难。改进建议是结合视觉-语言模型(VLMs),通过分析任务视频自动生成评价函数或人类反馈。
- 对模拟环境的依赖:研究主要在模拟环境中进行,缺乏对真实机器人任务的广泛验证。建议扩展到更多真实世界的任务,并探索更高效的Sim2Real方法。
- 缺乏对多任务学习的探索:EUREKA目前针对单一任务生成奖励函数,尚未探索多任务场景下的奖励生成机制。建议研究如何在多任务学习中共享奖励设计知识。
- 对LLM性能的依赖:尽管实验表明EUREKA在使用性能较低的GPT-3.5时仍能取得较好结果,但其性能仍然受限于LLM的能力。未来可以探索结合更高效的编码模型或领域特化模型。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 创新点1:开发基于视觉-语言模型的任务描述与奖励生成框架,将任务视频直接作为输入,自动生成奖励函数。
- 创新点2:研究多任务奖励生成机制,探索如何通过共享知识在多个任务中提升奖励生成效率和性能。
- 创新点3:将EUREKA扩展到真实机器人环境,结合Sim2Real技术验证其在实际任务中的适用性,并探索对物理参数变化的鲁棒性。
-
为新的研究路径制定的研究方案:
-
研究方案1:基于视觉-语言模型的任务描述与奖励生成
- 目标:开发一个框架,利用视觉-语言模型从任务视频生成任务描述和奖励函数。
- 研究方法:
- 利用预训练的视觉-语言模型(如BLIP-2或MiniGPT-4)对任务视频生成自然语言任务描述。
- 将生成的任务描述与环境代码结合,输入EUREKA框架生成奖励函数。
- 在标准RL环境中评估生成奖励的性能,并与人工设计的奖励进行对比。
- 期望成果:
- 生成的奖励函数能够有效提升RL算法的学习效率。
- 验证视觉-语言模型在任务理解和奖励生成中的潜力。
-
研究方案2:多任务奖励生成机制
- 目标:研究如何通过共享知识在多个任务中提升奖励生成的效率和性能。
- 研究方法:
- 构建多个相关任务的环境(例如不同形态的机器人任务)。
- 在EUREKA中引入跨任务的奖励生成模块,利用任务间的相似性共享奖励设计知识。
- 评估共享奖励生成机制在不同任务中的性能提升。
- 期望成果:
- 提出一种高效的多任务奖励生成算法。
- 验证奖励共享机制在复杂任务中的适用性。
-
研究方案3:扩展至真实机器人环境
- 目标:将EUREKA扩展到真实机器人任务,验证其在实际应用中的适用性。
- 研究方法:
- 选择一个典型的真实机器人任务(例如机械臂抓取或移动机器人导航)。
- 结合Sim2Real技术,将EUREKA生成的奖励函数应用于真实机器人。
- 通过实验验证奖励函数在真实环境中的鲁棒性和性能。
- 期望成果:
- 提供EUREKA在真实机器人任务中的性能评估。
- 提出改进Sim2Real的奖励设计方法。
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!